2일 차 회고
오늘부터 본격적인 수업이 시작되었다. 아직 2일 차라서 그런지 아침에 일어나는 것이 힘들다. 그래도 수업을 들을 때는 열심히 집중해서 들었다. 아직 기본적인 내용을 배워서 괜찮았지만, 나중에 AI에 대해 본격적으로 배우게 될 때 잘할 수 있을지가 벌써부터 걱정이다. 그리고 블로그도 써보는 것이 처음이라 많은 시행착오를 겪게 될 것 같다. 이 교육이 끝날 때에는 나만의 개발 블로그를 잘 구축할 수 있었으면 좋겠다.
0. 프로젝트 단위로 개발
개발은 프로젝트 단위로 진행하는 것이 좋다.
VS Code에서도 프로젝트 단위로 폴더를 생성하고, github에서도 프로젝트 단위로 레퍼지토리를 생성하도록 한다.
1. 가상환경 구축
1-1 가상환경 생성
Python의 개발을 위해 가상환경을 생성한다.
py -3.12 -m venv .venv # .venv 디렉토리에 Python 3.12 버전의 가상환경 생성
가상환경이 생성된 것은 옆의 Explorer 탭에서 또는 ls 명령어로 확인할 수 있다.
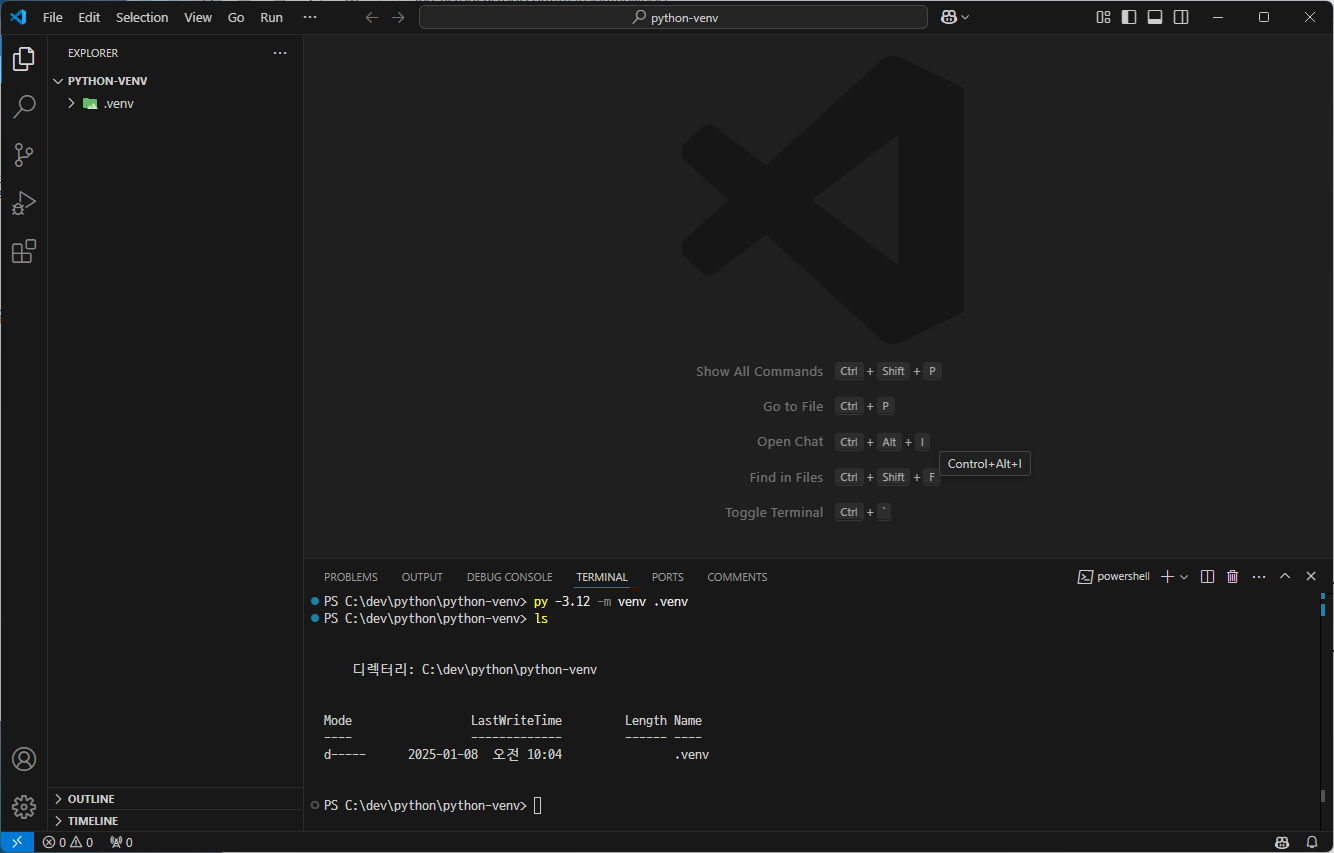
다음의 명령어를 통해 가상환경을 활성화하거나 비활성화할 수 있다.
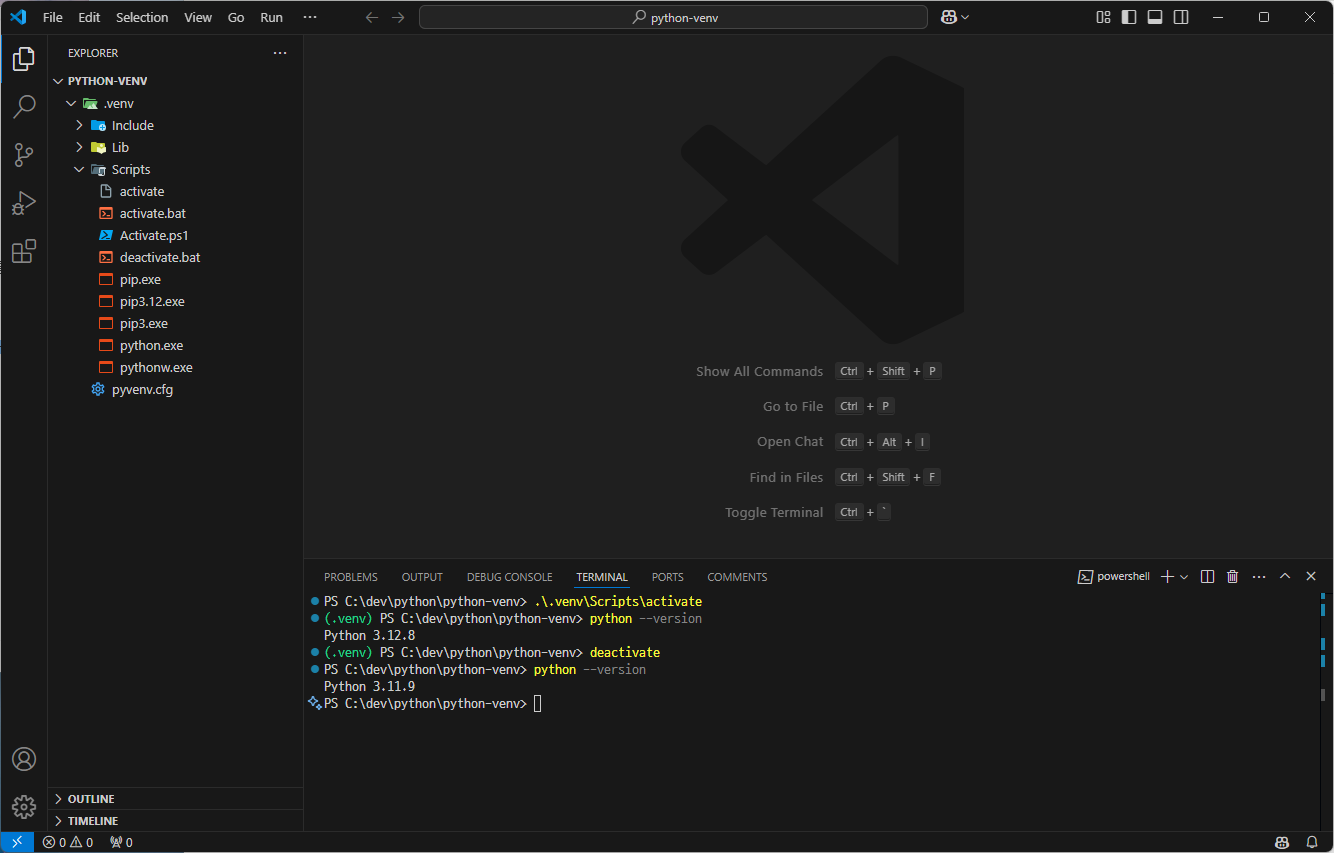
파일 경로 앞에 (.venv)가 붙은 것을 통해 가상환경이 활성화된 것을 확인할 수 있다.
또한, 가상환경 내에서는 해당 가상환경을 만들 때 사용한 버전만 사용할 수 있다.
.\.venv\Scripts\activate # 가상환경 활성화
py --version # 가상환경 Python 버전 확인
deactivate # 가상환경 비활성화
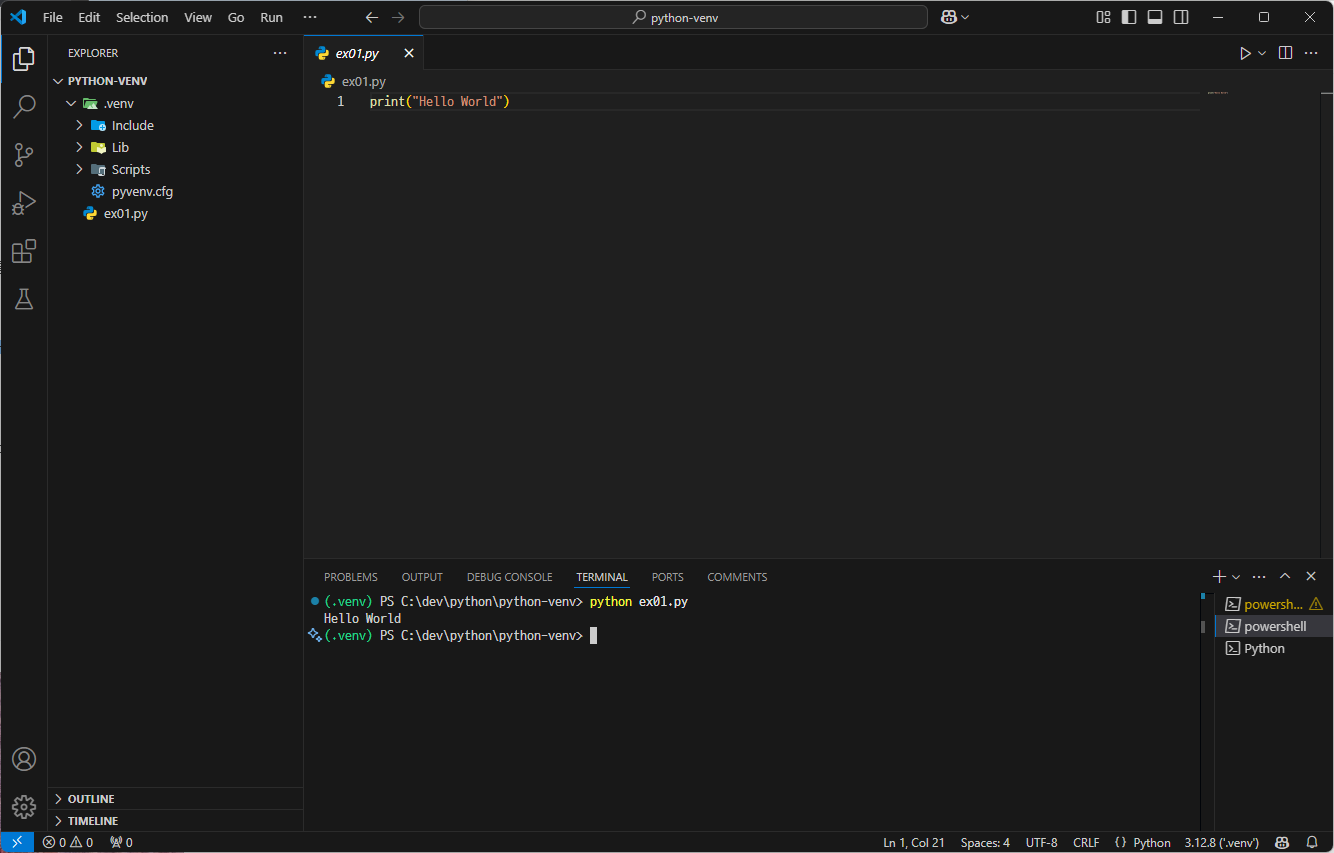
가상환경을 생성하였다면, 새 Python 파일을 만들어 코드를 작성한다.
이때, 가상환경에서 실행하기 위해서는 우측 하단에 있는 파이썬 버전을 클릭하여 가상환경(Recommend)을 선택한다.
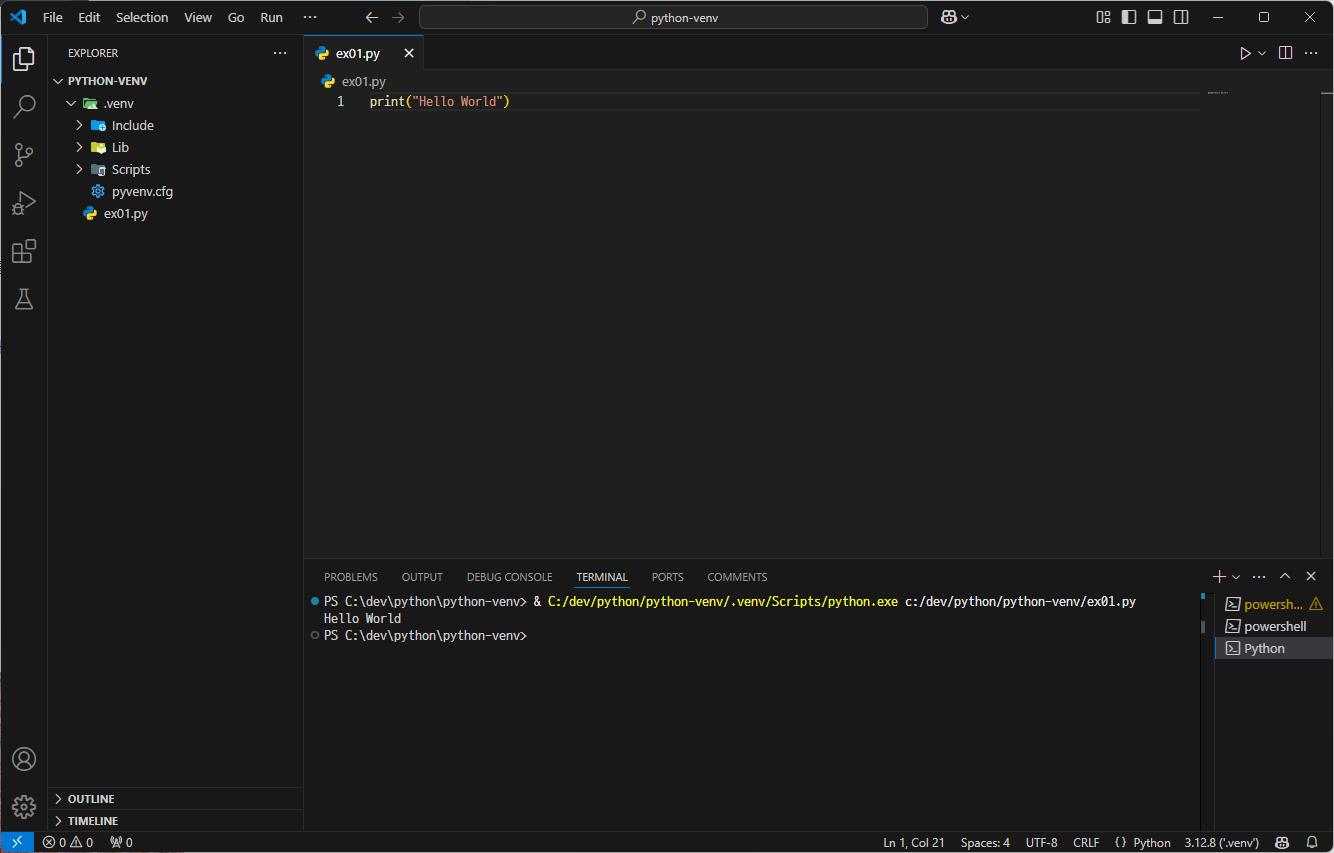
Python 파일의 실행 방법에는 두 가지가 있다.
첫 번째 방법은 Terminal에서 python [파일 이름].py 명령어를 실행하는 것이고,
두 번째 방법은 VS Code 내에서 'Run Python File'을 통해 실행하는 것이다.
1-2. 가상환경에 모듈 설치
모듈을 설치하기 전에 pip를 최신 버전으로 업그레이드한다.
python -m pip instsall --upgrade pip
pip을 최신 버전으로 업그레이드했다면, 다음 명령어를 통해 numpy를 설치한다.
pip install numpy

새 Python 파일을 만들어 해당 코드를 작성하여 실행한다.
import numpy
print("Hi Numpy")
가상환경에 numpy를 설치했기 때문에 가상환경 내에서는 실행이 되지만, 가상환경을 비활성화한 상태에서 실행한 경우, 모듈이 설치되지 않아 ModuleNotFoundError가 뜬다.
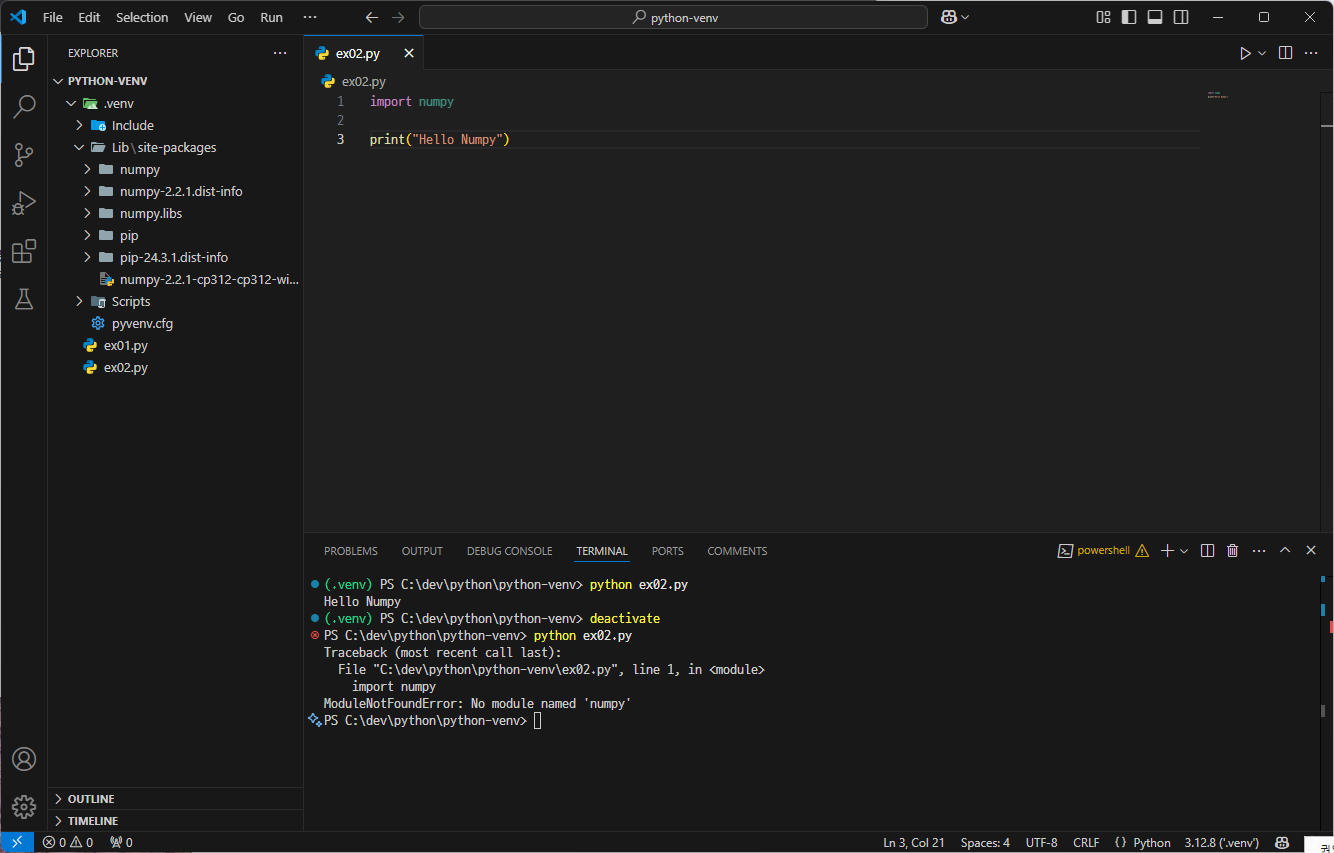
seaborn의 경우도 마찬가지이다.
1-3. requirements.txt로 모듈 설치
Terminal에 해당 명령어를 작성한다.
pip freeze > requirements.txt # 설치된 pip 패키지 목록을 requirements.txt 파일에 작성

requirements.txt 파일이 생성된 것을 확인한 후, 기존의 가상환경과 동일한 Python 버전의 새로운 가상환경을 만든다.
그리고 새 파일을 생성하여 다음과 같은 코드를 작성한다.
import numpy
import seaborn
print("Hello World")
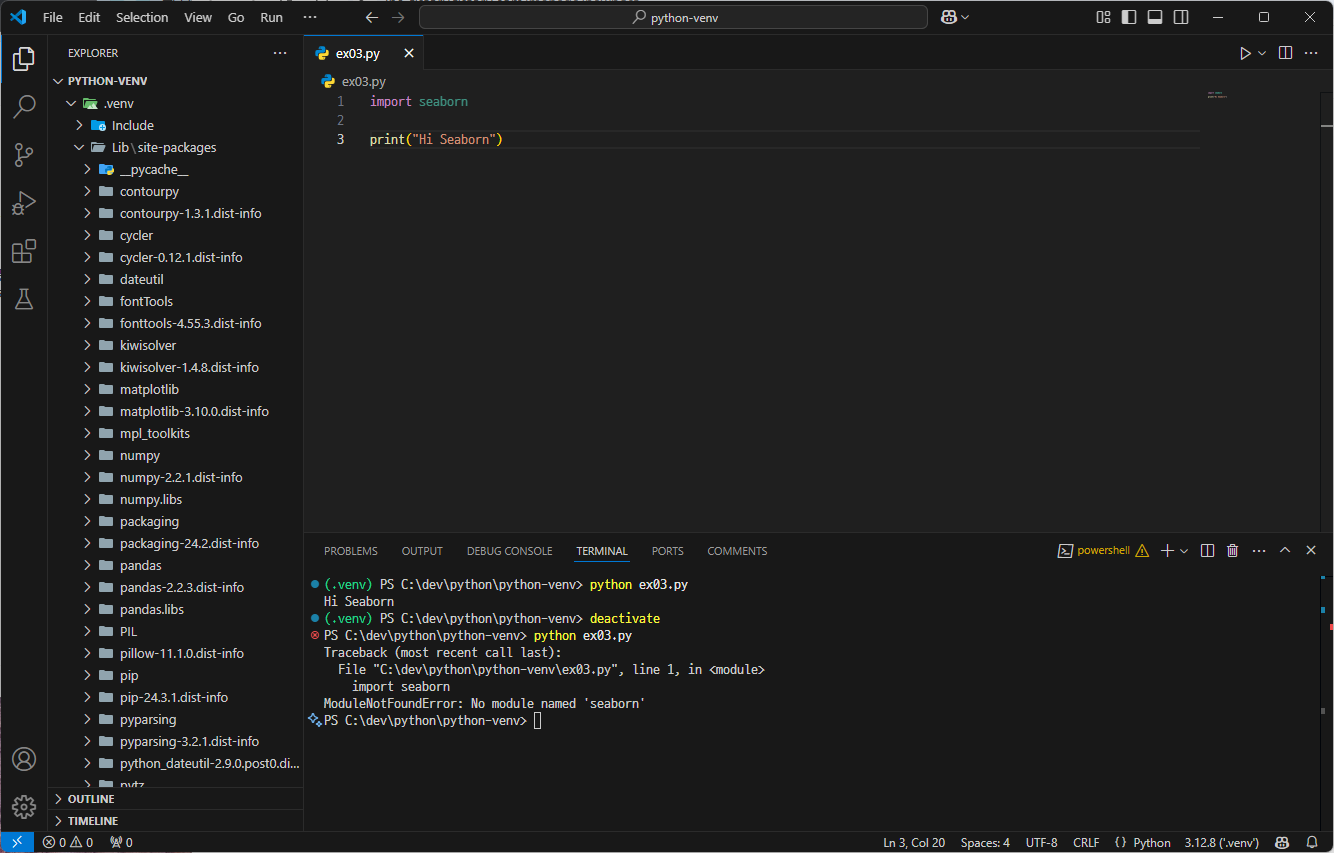
해당 가상환경에는 numpy, seaborn이 설치되지 않아 오류가 뜨는 것을 확인할 수 있다.

앞에서 만들었던 requirements.txt 파일을 해당 폴더로 옮긴 후, 다음 명령어를 실행한다.
pip install -r requirements.txt # r: read
requirements.txt 파일에 있는 pip 패키지들이 설치되는 것을 확인할 수 있다.
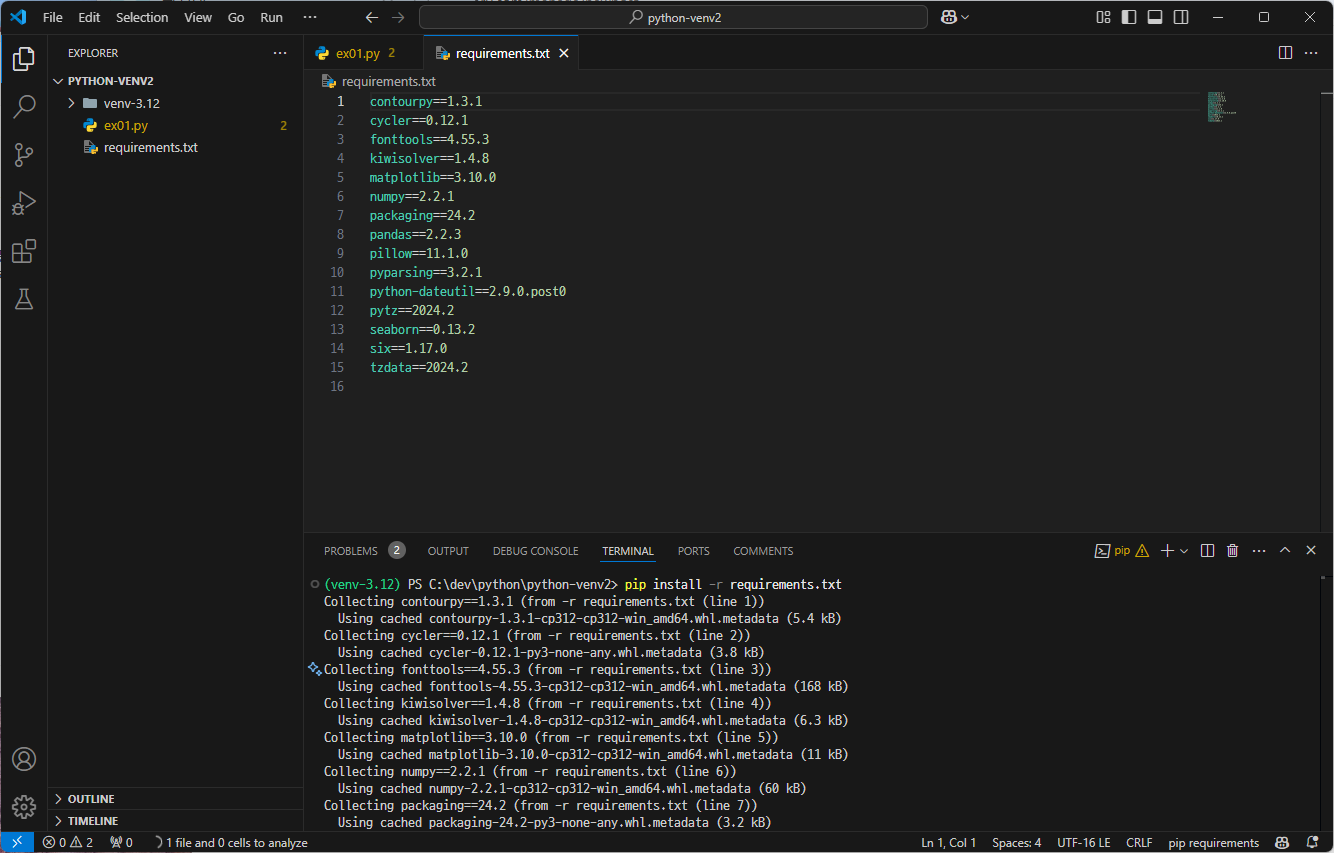
설치를 완료한 후, ex01.py 파일을 실행하면 정상적으로 실행되는 것을 확인할 수 있다.
또한, 앞에서와 마찬가지로 가상환경을 비활성화하여 파일을 실행하면 에러가 뜨는 것을 확인할 수 있다.

2. 자료구조
2-1. 변수(Variable)
새로운 프로젝트를 생성하여 Terminal에서 다음 코드를 실행한다.
pip install jupyter
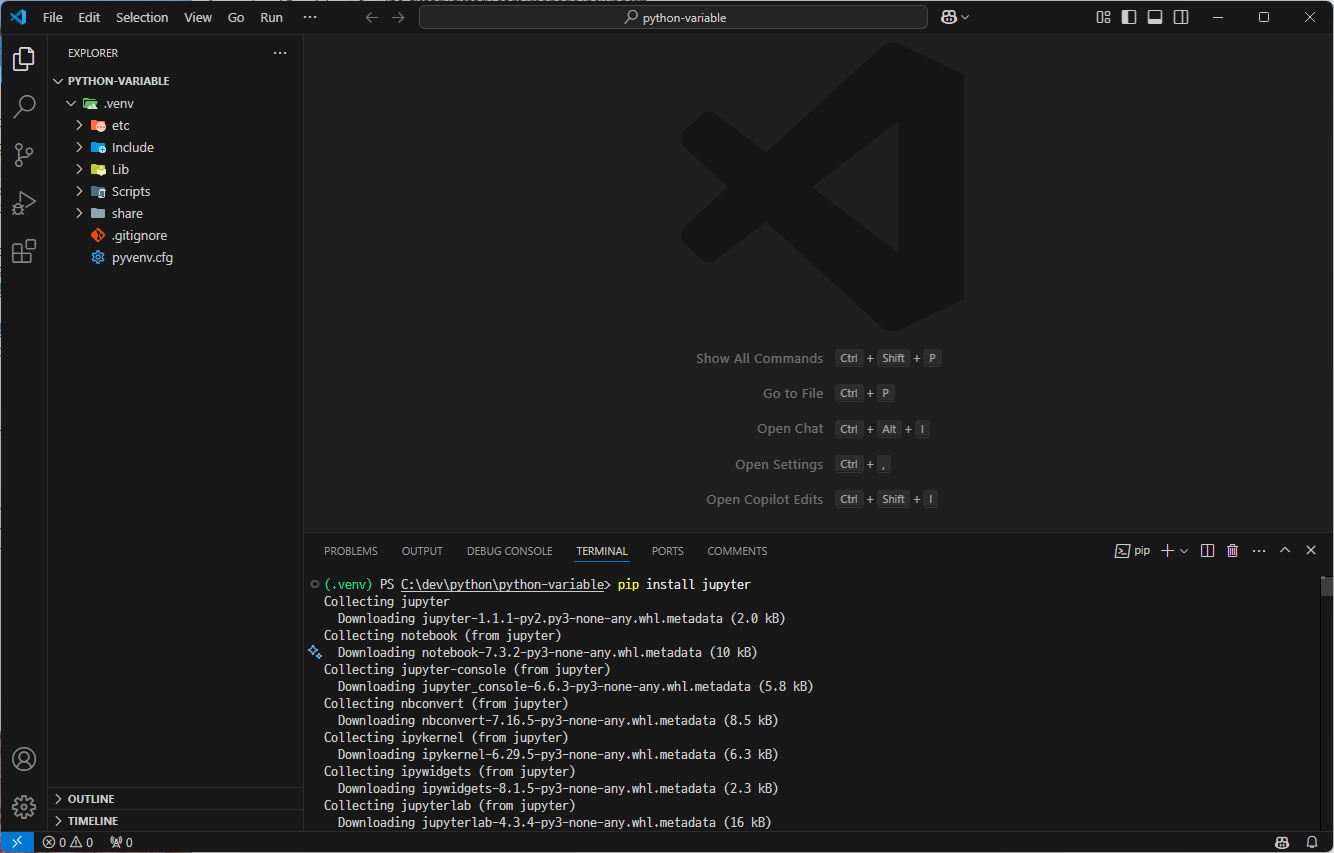
이로써 VS Code에서도 Jupyter Notebook을 사용할 수 있다.
먼저, Python 파일을 통해 다음 코드를 실행한다.
"""
'=' (대입연산자)
-> 오른쪽의 데이터(객체)를 왼쪽에 적용시킴
"""
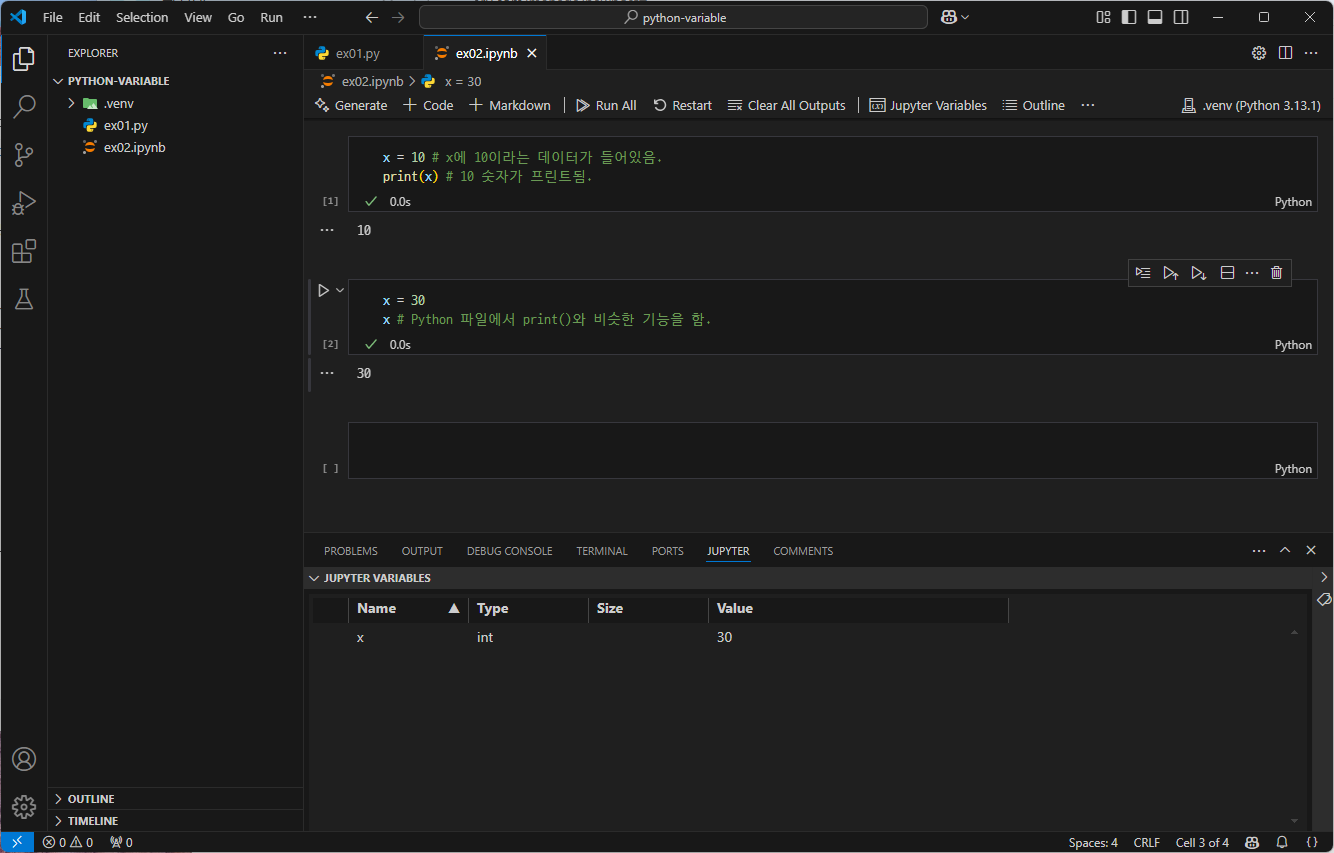
x = 10 # x에 10이라는 데이터가 들어있음.
print(x) # 10 숫자가 프린트됨.
이 코드는 Jupyter Notebook에서도 다음과 같이 실행할 수 있다.
이때, Select Kernel을 통해 가상환경에서 실행하도록 한다.
Jupyter에서는 <Shift> + <Enter> 키를 통해 실행 후 다음 줄로 넘어갈 수 있다.
Jupyter Variables 탭을 통해 선언된 변수들을 확인할 수 있다.
여기서 변수(variable)는 쉽게 말해 변할 수 있는 수를 말한다.

x는 변수이므로 다음과 같이 새로 선언하여 값을 변경할 수 있다. x의 type는 int로, 정수(integer)를 말한다.
y에 실수(real number)를 대입해 보면 type은 float가 된다.

z에는 문자열을 대입해 본다. 이때, 문자열은 " " 또는 ' '를 사용하여 묶어줘야 한다.
문자열(string)은 str이며, size가 존재한다. size는 문자열의 길이와 동일하며, 띄어쓰기를 포함한다.

2-2. 변수표기법
우리가 개발을 할 때는 협업하는 경우가 많기 때문에 변수명을 예측하기 쉽게 지어야 한다.
name = "홍길동" # name 변수에는 str
age = 10 # age 변수에는 int
간단한 변수는 위처럼 표기하면 되지만,
두 개 이상의 단어로 이루어진 변수를 표기할 때에는 보통 카멜 케이스와 스네이크 케이스를 사용한다.
카멜 케이스(camelCase)는 첫 번째 단어를 제외한 나머지 단어의 첫 글자를 대문자로 표기하는 것이고,
스네이크 케이스(snake_case)는 단어들을 _를 이용하여 연결하는 것이다.
student_name = "홍길동" # snake_case
studentAge = 30 # camelCase
2-3. 구구단
구구단과 같이 반복적인 작업을 할 때는 변수가 유용하다.
구구단 2단을 7단으로 바꾸기 위해서는 2를 모두 7로 바꿔야 한다.
이럴 경우, 실수가 발생할 확률이 높아 효율적이지 않다.
print(2 * 1)
print(2 * 2)
print(2 * 3)
print(2 * 4)
print(2 * 5)print(7 * 1)
print(7 * 2)
print(7 * 3)
print(2 * 4) # 오류 발생
print(7 * 5)
변수를 선언하게 되면 반복적인 작업을 줄이고, 실수도 줄일 수 있다.
number = 7
print(number * 1)
print(number * 2)
print(number * 3)
print(number * 4) # 오류 X
print(number * 5)
2-4. 비교연산자
'='이 하나면 데이터를 대입한다는 의미이고, '=='처럼 두 개이면 데이터가 같은지 비교하는 것이다.
"""
'=': 오른쪽에 있는 데이터를 왼쪽에 대입
'==': 오른쪽과 왼쪽이 같은지 비교 -> 같으면 True / 다르면 False
"""
num1 == num2 # 10 == 30 -> False
'!='는 데이터가 다른지 비교하는 것이다.
"""
'!=': 오른쪽과 왼쪽이 다른지 비교 -> 다르면 True / 같으면 False
"""
num1 != num2 # 10 != 30 -> True
이외에도 is / is not을 이용하여 데이터를 비교할 수 있다.
하지만, '=='와 '!='는 변수의 값을 비교하는 것이고, is와 is not은 변수의 주소를 비교하는 것으로 차이가 있다.
"""
같은지 다른지 비교하는 명령어
'==' / '!=': 변수(데이터)를 비교 -> num1 == num2 -> 1001 == 1001 -> True
is / is not: 변수(주소)를 비교 -> num1 == num2
"""
num1 is num2 # False
변수의 주소는 다음과 같이 확인할 수 있다.
id(num1), id(num2)
2-5. 상수(Constant)
변수와 달리 상수는 데이터를 수정할 수 없다. 일반적으로 상수는 대문자로 이름을 정한다.
하지만 별다른 설정을 하지 않으면 데이터를 수정할 수 있어 별다른 조치가 필요하다.
"""
변수: 데이터를 수정할 수 있음
상수: 데이터를 수정할 수 없음
"""
DEFAULT = 1010
DEFAULT = 2020 # 데이터를 수정하는 행위 -> 오류 발생 / 만약 오류가 발생하지 않으면 -> 변수
DEFAULT # 2020 -> 변수
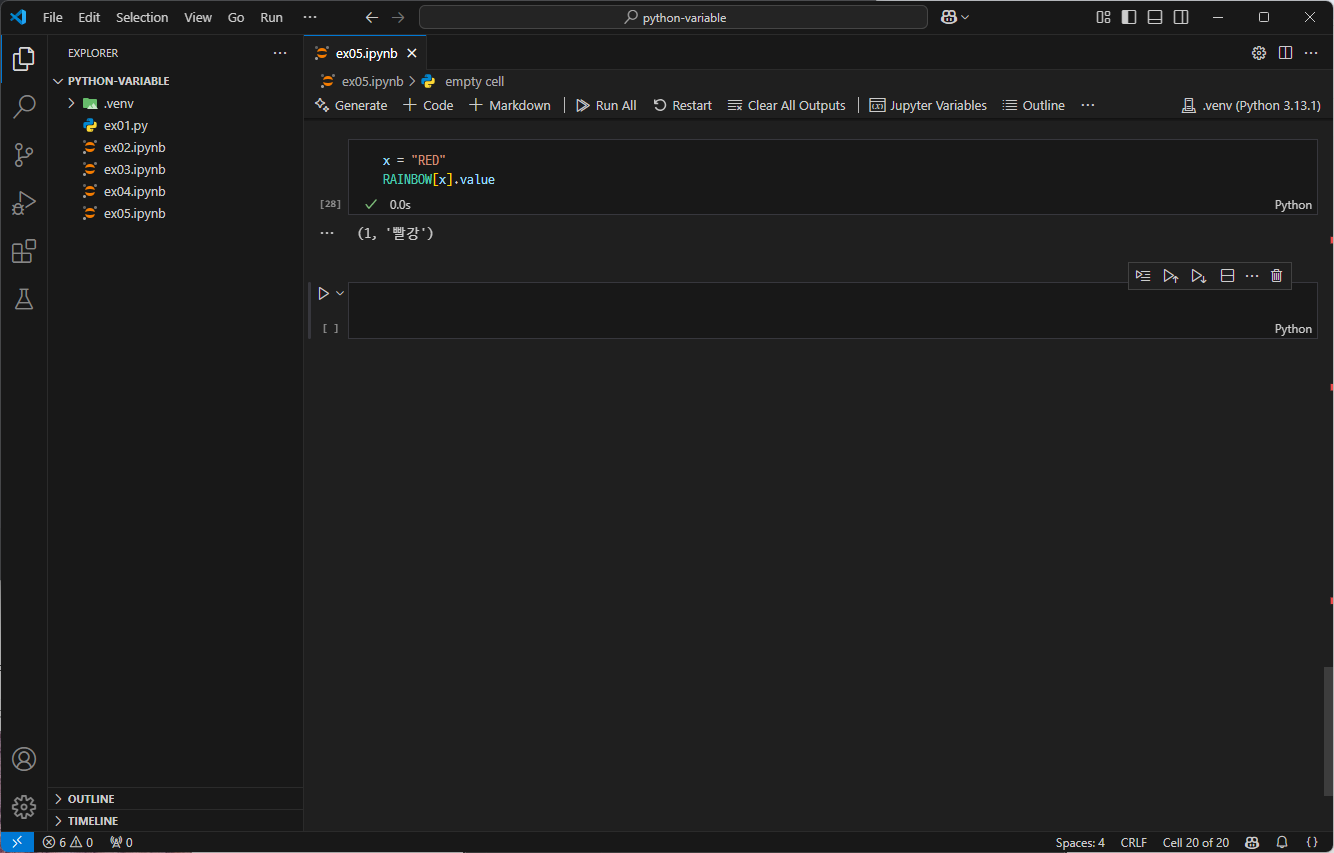
따라서 enum을 사용하여 RAINBOW 클래스를 통해 상수를 만든다.
class RAINBOW(enum.Enum):
# 상수를 선언하자!!!
RED = (enum.auto(), "빨강")
PURPLE = (enum.auto(), "보라")
이러한 방법으로 상수를 선언하면 Attribute Error로 데이터를 변경할 수 없다.

변수와 마찬가지로 상수 또한 데이터를 조회할 수는 있다. 하지만 변수와는 달리 데이터를 변경할 수는 없다.

변수와 마찬가지로 상수 또한 데이터를 비교할 수 있다.

다음과 같은 방법으로 RAINBOW 클래스에 있는 데이터를 모두 조회할 수 있다.
in 명령어를 통해서 데이터가 해당 클래스에 들어있는지 알 수 있다.


변수를 사용하여 데이터를 조회하고 싶은 경우, 다음과 같이 코드를 작성할 수 있다.
4-6. 인덱싱(Indexing)
변수의 타입과 길이는 다음과 같은 명령어로 확인할 수 있다.

문자열의 경우 각 글자를 구분하여 출력할 수 있다. 이를 인덱싱이라고 한다.
앞에서부터 판단할 경우, 첫 글자의 인덱스는 0이다. 뒤에서부터 판단할 경우, 마지막 글자의 인덱스는 -1이다.

4-7. 슬라이싱(Slicing)
슬라이싱은 인덱스를 이용하여 문자열을 잘라 출력할 수 있다.
변수명[시작위치 : 끝위치]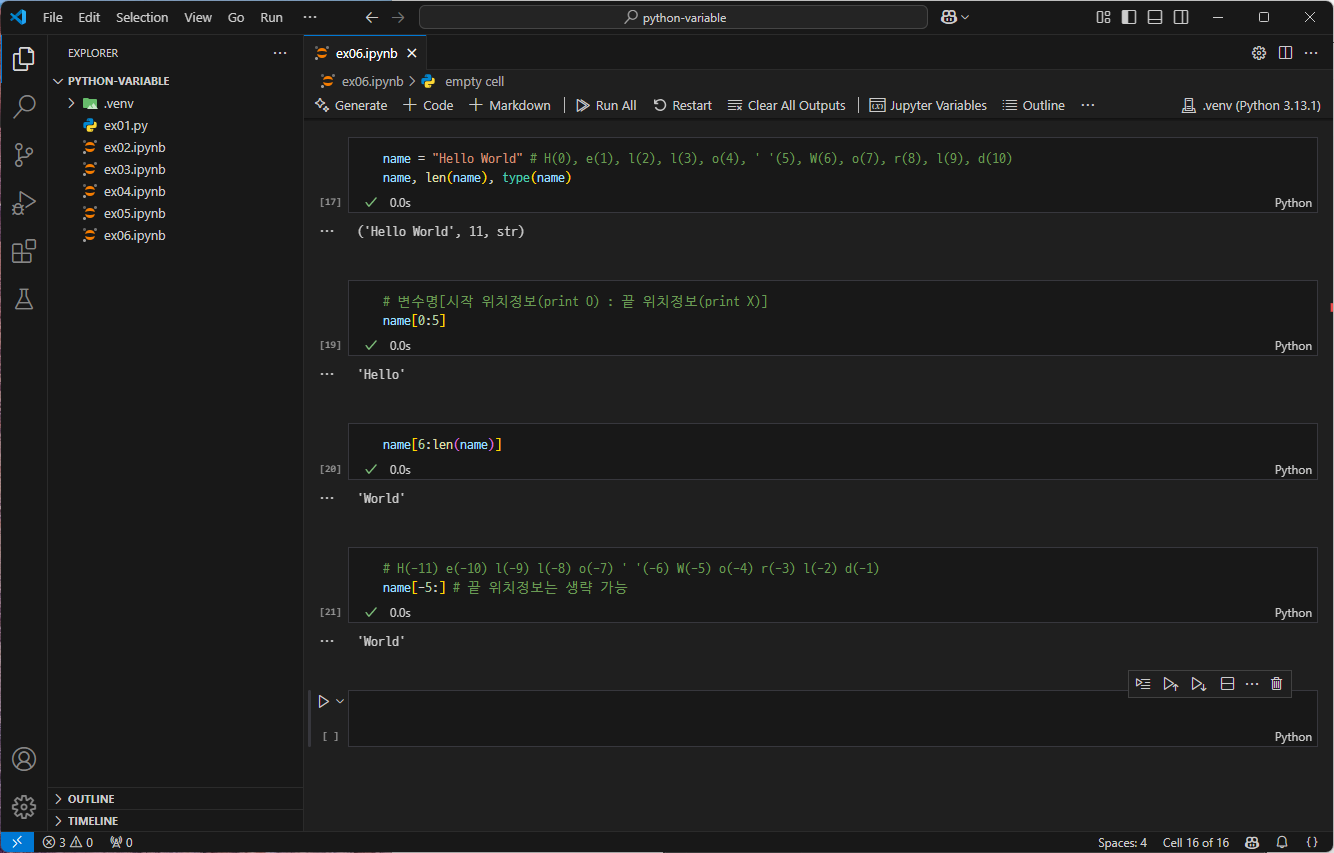
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 6일차. 함수 & 클래스 (0) | 2025.01.14 |
|---|---|
| 5일차. 함수 (0) | 2025.01.13 |
| 4일차. 제어문 & 예외 처리 (0) | 2025.01.10 |
| 3일차. 자료구조 & 제어문 (0) | 2025.01.09 |
| 1일차. 개발 환경 구축 (0) | 2025.01.07 |



