35일 차 회고.
벌써 2월 마지막 날이라서 시간이 빨리 간다고 느껴졌다. 2개월동안 아직 이룬 것이 없어서 초조해지기도 하는 것 같다. 가뜩이나 이번 단위 프로젝트에서 머신러닝 모델의 결과가 별로 좋지 않아서 스트레스 받기도 하는 것 같다. 일단 주말에 최대한 높여보고 월요일에 화면 구현을 할 예정이다.
4. 추천 시스템 - Item Based Filtering 부터 수정
1. 추천 시스템
추천 시스템은 정보 필터링 기술의 일종으로 특정 사용자가 관심을 가질만한 정보를 추천하는 것이다.
1-1. Cold Start
Cold Start는 추천 시스템이 새로운 또는 일부 유저들에 대한 충분한 정보가 수집된 상태가 아니기 때문에 해당 유저들에게 적절한 제품을 추천해주지 못하는 문제를 말한다.
Cold Start 발생 원인
- New Community
- 새로운 서비스가 오픈된 경우
- New Item
- 새로운 제품이 출시된 경우
- New User
- 새로운 유저가 가입한 경우
Cold Start 해결 방법
- New Community
- Knowledge-Based Filtering
- New Item
- Content-Based Filtering
- New User
- Knowledge-Based Filtering
- 비개인화 추천 알고리즘
1-2. 추천 시스템의 필요성
추천 시스템은 고객 개개인에게 맞춤형 서비스를 제공함으로써 기업에는 더 많은 수익 창출을 제공하고, 고객에게는 더 높은 만족도를 제공한다.
파레토 법칙
- 전체 결과의 80%가 전체 원인의 20%에 의해 일어나는 현상
롱테일 법칙
- 80%의 사소한 다수가 20%의 핵심 소수보다 더 뛰어난 성과를 창출한다는 이론
1-3. 추천 시스템 분류
시나리오에 따른 분류
- 연관된 아이템 추천
- 개인화 아이템 추천
피드백 종류에 따른 분류
- 명시적 피드백(Explicit Feedback) 추천
- ex. 별점, 좋아요 등
- 암시적 피드백(Implicit Feedback) 추천
- 조회수, 검색 기록, 페이지 유지 시간 등
1-4. 추천 알고리즘
비개인화 추천 알고리즘
- 인기도 기반 추천
- 조회수 기반 추천(Most Popular)
- ex. Hacker News Ranking Algorithm
- $score = \frac {pageviews - 1} {(age + 2)^{gravity}}$
- $pageviews$: 조회수
- $age$: 현재 시각 - 기사 업로드 날짜
- $gravity$: 중력 상수
- $score = \frac {pageviews - 1} {(age + 2)^{gravity}}$
- ex. Hacker News Ranking Algorithm
- 평점 기반 추천(Highly Rated)
- ex. Stream Ranking Algorithm
- $score = avg\;rating - (avg\;rating - 0.5) × 2^{-log_{10}(num\,of\,reviews)}$
- $avg\;rating : \frac {긍정 리뷰 수} {전체 리뷰 수}$
- $score = avg\;rating - (avg\;rating - 0.5) × 2^{-log_{10}(num\,of\,reviews)}$
- ex. Stream Ranking Algorithm
- 조회수 기반 추천(Most Popular)
Knowledge-Based Filtering
- 추천하고자 하는 분야의 도메인 지식을 활용해 추천하는 방식
- ex. 성별, 나이 등
Content-Based Filtering
- 추천하려는 아이템의 메타 정보를 활용해 콘텐츠별로 특징 정보를 만들어 이를 활용해 추천하는 방식
Collaborative Filtering

- Memory-Based Algorithm
- User-Based Filtering
- 사용자 간의 유사성을 기반으로 추천하는 방식
- 사용자의 선호도는 시간이 지나면서 바뀔 수 있다.
- Item-Based Filtering
- 사용자의 이력을 기반으로 추천하는 방식
- User-Based Filtering
- Model-Based Algorithm
- 행렬 분해를 통해 잠재 요인을 추출하여 추천하는 방식
Hybrid Recommender System
- Content-Based Filtering 방식과 Collaborative Filtering 방식을 결합하여 아이템마다 가중평균을 구해 랭킹을 구하는 방식
1-5. 추천 평가 지표
Precision@K
- 내가 추천한 아이템 K개 중에 실제 사용자가 관심 있는 아이템의 비율
Recall@K
- 실제 사용자가 관심 있는 모든 아이템 중에서 내가 추천한 아이템 K개의 비율
Mean Average Precision@K
- 성능 평가에 순서 개념을 도입한 평가 지표
NDCG@K
- 추천된 아이템들의 순서를 고려한 평가 지표
Hit Rage@K
- 전체 사용자 수 대비 적중한 사용자 수
2. 추천 시스템 - 인기도 기반 추천
2-1. Import Modules
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
from ast import literal_eval
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarityfrom google.colab import drive
drive.mount('/content/data')
2-2. Hotel Reviews
DATA_PATH = ''
hotel_reviews = pd.read_csv(DATA_PATH + 'Hotel_Reviews.csv')
2-3. Most Popular
df_reviews = hotel_reviews.copy()
df_reviews = df_reviews[['Hotel_Name', 'days_since_review']]
Hacker News Ranking Algorithm
def hacker_news_score(pageviews, age, gravity=1.8):
return (pageviews - 1) / pow((age + 2), gravity)
Score
- pageviews
pageviews = df_reviews['Hotel_Name'].value_counts()
df_reviews['paregiews'] = df_reviews['Hotel_Name'].map(pageviews)- age
df_reviews['days_since_review'] = df_reviews['days_since_review']\
.map(lambda x: int(x.replace('days', '').replace('day', '').replace(' ', '')))
df_reviews = df_reviews.groupby(['Hotel_Name']).agg({'days_since_reviews':'min'})\
.sort_values(by='days_since_review', ascending=False).reset_index()
df_reviews.rename(columns={'days_since_review':'age'}, inplace=True)- score
df_reviews['score'] = df_reviews.apply(
lambda row: hacker_news_score(row['pageviews'], row['age']), axis=1
)
추천
no_ranking = 5
df_reviews.sort_values(by=['score'], ascending=False)[:no_ranking]
2-4. Highly Rated
df_reviews = hotel_reviews.copy()
df_reviews = df_reviews[['Hotel_Name', 'Reviewer_Score']]
Steam Rating Algorithm
def GetRating(positive_votes, negative_votes, standard_score=0.5):
total_votes = positive_votes + negative_votes
average = positive_votes / total_votes
score = average - (average - standard_score)*2**(-np.log10(total_votes + 1))
return score * 100
Score
df_score_max = df_reviews[df_reviews['Reviewer_Score'] >= 7]\
.groupby(['Hotel_Name']).agg({'Reviewer_Score':'count'}).reset_index()
df_score_min = df_reviews[df_reviews['Reviewer_Score'] < 7]\
.groupby(['Hotel_Name']).agg({'Reviewer_Score':'count'}).reset_index()
df_score = pd.merge(df_score_max, df_score_min, on='Hotel_Name', how='inner')
df_score['score'] = df_score.apply(lambda row: GetRating(row['score_max'], row['score_min']), axis=1)
추천
no_ranking = 5
df_score.sort_values(by=['score'], ascending=False)[:no_ranking]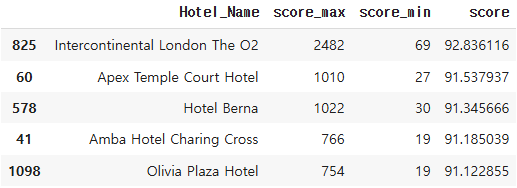
3. 추천 시스템 - Contents Based Filtering
3-1. 코사인 유사도

$similarity = cos(\theta) = \frac {A × B} {|A| |B|} = \frac {\sum^n_{i=1} A_i × B_i} {\sqrt{\sum^n_{i=1}(A_i)^2} × \sqrt{\sum^n_{i=1}(B_i)^2}}$
3-2. Movie Dataset
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
from ast import literal_eval
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import consine_similarityfrom google.colab import drive
drive.mount('/content/data')DATA_PATH = ''
movies = pd.read_csv(DATA_PATH + 'tmdb_5000_movies.csv')
필요한 컬럼 선택
movies = movies[['id', 'genres', 'overview', 'title', 'vote_average', 'vote_count']]
def genres_to_str(genres) -> str:
try:
_genres_list = json.loads(genres)
_genres_list = sorted([i['name'] for i in _genres_list])
_genres_str = ' '.join(_genres_list)
return _genres_str
except:
return genres
movies['genres'].map(lambda x: genres_to_str(x))[:5]
결측치 확인
movies = movies.dropna()
genres 가공
movies['genres'] = movies['genres'].apply(literal_eval)
movies['genres'] = movies['genres'].map(lambda x: [y['name'] for y in x])
movies['genres'] = movies['genres'].apply(lambda x: (' ').join(x))
3-3. Model with Score
가중 평점(Weighted Rating)
- 가중 평점 = $\frac {v} {v + m} * R + \frac {m} {v + m} * C$
- $v$: 영화에 평가를 매긴 횟수
- $m$: 평점을 부여하기 위한 최소 평가 수
- $R$: 영화의 평균 평점
- $C$: 전체 영화의 평균 평점
percentile = 0.6
m = movies['vote_count'].quantile(percentile)
C = movies['vote_average'].mean()
def weighted_rating(recored):
v = record['vote_count']
R = record['vote_average']
return ((v / (v + m)) * R) + ((m / (m + v)) * C)
movies['weighted_rating'] = movies.apply(weighted_rating, axis=1)
추천
movies[['title', 'weighted_rating', 'vote_average', 'vote_count']]\
.sort_values(['weighted_rating', 'vote_average', 'vote_count'], ascending=False)[:10]
3-4. Model with Count
df_movies = movies.copy()
CountVectorizer
- 단어들의 출현 빈도로 여러 문서들을 벡터화한다.
count_vect = CountVectorizer(min_df=0.01, ngram_range=(1, 2))
len(count_vect.vocabulary_.keys())
# 61
genre_mat = count_vect.fit_transform(df_movies['genres'])
genre_mat.toarray()
# array([[1, 1, 0, ..., 0, 0, 0],
# [1, 0, 0, ..., 0, 0, 0],
# [1, 1, 0, ..., 0, 0, 0],
# ...,
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0]])
유사도 측정
genre_sim = cosine_similarity(genre_mat, genre_mat)
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1]
추천
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n*1)]
similar_indexes = similar_indexes.reshape(-1)
similar_indexes = similar_indexes[similar_indexes != title_index]
return df.iloc[similar_indexes].sort_values('weighted_rating', ascending=False)[:top_n]
similar_movies = find_sim_movie(df_movies, genre_sim_sorted_ind, 'No Country for Old Men', 10)
similar_movies[['title', 'vote_count', 'weighted_rating']]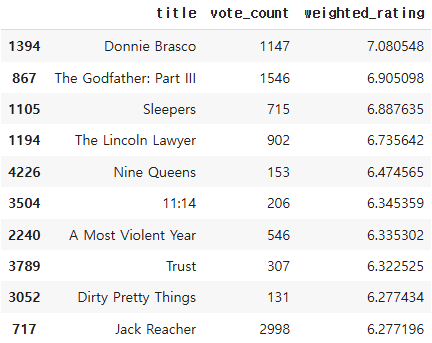
3-5. Model with TF-IDF
df_movies = movies.copy()
TF-IDF
- 모든 문서에 공통적으로 들어있는 단어의 경우, 문서 구별 능력이 떨어진다고 보아 가중치를 축소하는 방법
from sklearn.feature_extraction.text import TfidVectorizer
df_movies['features'] = df_movies['genres'] + df_movies['overview']
tfidf_vect_simple = TfidVectorizer(Stop_words='english')
genre_vector = genre_mat.toarray()
유사도 측정
similarity = cosine_similarity(genre_vector)
추천
def recommend(movie):
movie_index = df_movies[df_movies['title'] == movie].index[0]
distances = similarity[movie_index]
movies_list = sorted(list(enumerate((distances)), reverse=True, key=lambda x: x[1]) [1:16]
mov = []
id = []
scores = []
for i in movies_list:
mov.append(df_movies.iloc[i[0]].title)
id.append(df_movies.iloc[i[0]].id)
scores.append(i[1])
dic = {'movie_id': id, 'title': mov, 'Similarity Score': scores, 'weighted_rating': rating}
df_recommend = pd.DataFrame(dic)
return df_recommend.sort_values('weighted_rating', ascending=False)[:top_n]
movie_name = 'Pirates of the Caribbean: On Stranger Tides'
popular_movies = recommend(movie_name)import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = (10, 9)
sns.barplot(x=popular_movies['Similarity Score'], y=popular_movies['title'], palette='tab20')
plt.show()
plt.rcParams['figure.figsize'] = (10, 9)
sns.barplot(x=popular_movies['weighted_rating'], y=popular_movies['title'], palette='tab20')
plt.show()
4. 추천 시스템 - Item Based Filtering
4-1. Movie Dataset
import pandas as pd
import numpy as np
import scipy.stats
import seaborn as snsfrom google.colab import drive
drive.mount('/content/data')DATA_PATH = ''
rating = pd.read_csv(DATA_PATH + 'rating.csv')
movies = pd.read_csv(DATA_PATH + 'movies_metadata.csv')from ast import literal_eval
4-2. Model with Cosine Similarity
5. 추천 시스템 - Deep FM
5-1. Deep FM
Model Structure

- Dense Embeddings
- FM Component와 Deep Component가 같은 Embedding Layer를 공유한다.
- Field vector의 크기가 다를 수 있지만, Embedding Layer로 인해 같은 크기를 가진다.
- Pre-trained할 필요가 없고, End-to-End로 학습한다.
- FM Component와 Deep Component가 같은 Embedding Layer를 공유한다.
5-2. 코드
from google.colab import drive
drive.mount('/content/data/')
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 38일차. 자연어 데이터 준비 - NLP & Integer Encoding & Word2Vec (0) | 2025.03.06 |
|---|---|
| 36-37일차. 단위 프로젝트(데이터 분석과 머신러닝, 딥러닝) (0) | 2025.03.05 |
| 34일차. Deep Learning - Modular & TensorBoard & HPO Tuning (0) | 2025.02.27 |
| 33일차. Deep Learning - Vision(Fine Tuning) (0) | 2025.02.26 |
| 32일차. Deep Learning - Vision(CNN & Fine Tuning) (0) | 2025.02.25 |



