더보기
45일 차 회고.
체력이 많이 떨어졌다는 게 느껴져서 다시 운동을 시작해야 할 것 같다.
1. GRU
1-1. GRU(Gated Recurrent Unit)
Update Gate
- LSTM의 Forget Gate와 Input Gate를 합친 Gate
- 이전의 정보를 얼마나 통과시킬지 결정한다.
Reset Gate
- 이전 Hidden State의 정보를 얼마나 잊을지를 결정한다.
1-2. 텍스트 생성(Text Generator)
텍스트 생성
- 인공지능이 기존의 텍스트로부터 새로운 텍스트를 생성하는 프로세스
활용분야
- 챗봇
- 인간 사용자와의 대화를 시뮬레이션하도록 설계된 컴퓨터 프로그램
- 언어 번역
- 텍스트를 한 언어에서 다른 언어로 변환하는 프로세스
1-3. GRU of 자연어 생성
Load Data
from google.colab import drive
drive.mount('/content/data')import numpy as np
import pandas as pd
from tqdm.auto import tqdm
data_path = ''
df = pd.read_csv(data_path + 'ArticlesApril2018.csv')
df.shape
# (1324, 15)
Cleaning
df['headline'] = df['headline'].map(lambda x: x.strip())
df = df[df['headline'] != 'Unknown']
df['headline'] = df['headline'].map(lambda x: x.encode('utf-8').decode('ascii', 'ignore'))
df['headline'] = df['headline'].map(lambda x: x.lower())
Tokenization
!python -m spacy download en_core_web_sm- Tokenizer 생성
import spacy
nlp = spacy.load('en_core_web_sm')- Stemming
def tokenizer(text):
tokens = nlp(text)
return [token.lemma_ for token in tokens if token.tag_[0] in 'NVJ']- 어휘집
!pip install -U torchtext==0.15.2
from torchtext.vocab import build_vocab_from_iterator
def yield_tokens(data, tokenizer):
for text in tqdm(data, desc='tokenizing', leave=False):
yield tokenizer(text)
gen = yield_tokens(df['headline'].tokenizer)
vocab = build_vocab_from_iterator(gen, specials=['<pad>', '<unk>'])
vocab.set_default_index(vocab['<unk>'])
len(vocab)
# 2744- Tokenization
sequences = []
for headline in tqdm(df['headline']):
token = vocab(tokenizer(headline))
for i in range(1, len(token)):
sequence = token[:i+1]
sequences.append(sequence)
sequences[:5]
# [[81, 308],
# [81, 308, 260],
# [81, 308, 260, 2389],
# [81, 308, 260, 2389, 312],
# [81, 308, 260, 2389, 312, 768]]
Padding
max_len = max([len(lst) for lst in sequences])
max_len
# 15
sequences = [[0] * (max_len - len(token)) + token for token in sequences]
sequences = np.array(sequences)
sequences.shape
# (4842, 15)
features = sequences[:, :-1]
targets = sequences[:, -1]
features.shape, targets.shape
# ((4842, 14), (4842,))
Dataset
import torch
from torch.utils.data import Dataset
class GeneratorDataset(Dataset):
def __init__(self, features, targets) -> None:
super().__init__()
self.x = features
self.y = targets
def __len__(self):
return self.x.shape[0]
def __getitem__(self, idx):
return {
'x': torch.tensor(self.x[idx]),
'y': torch.tensor(self.y[idx])
}
dt = GeneratorDataset(features, targets)
len(dt)
# 4842
DataLoader
from torch.utils.data import DataLoader
dl = DataLoader(dataset=dt, batch_size=128)
len(dl)
# 38
Model
- Embedding Layer
- Input: [batch, seq_len]
- Output: [batch, seq_len, emb_dim]
from torch import nn
class Embedding_Layer(nn.Module):
def __init__(self, vocab_len, emb_dim) -> None:
super().__init__()
self.emb = nn.Embedding(
num_embeddings=vocab_len,
embedding_dim=emb_dim
)
def forward(self, x):
return self.emb(x)- GRU Layer
- Input: [batch, seq_len, emb_dim]
- Output: [batch, n_hidden]
class GRU_Layer(nn.Module):
def __init__(self, emb_dim, n_hidden, device, n_layers=32) -> None:
super().__init__()
self.n_hidden = n_hidden
self.n_layers = n_layers
self.device = device
self.gru = nn.GRU(
input_size=emb_size,
hidden_size=self.n_hidden,
num_layers=self.n_layers
)
def forward(self, x):
input = x.transpose(0, 1)
init_hidden_state = torch.zeros(
1 * self.n_layers, x.shape[0], self.n_hidden
).to(self.device)
_, hidden_state = self.gru(input, init_hidden_state)
return hidden_state[-1]- FC Layer
- Input: [batch, n_hidden]
- Output: [batch, target_size]
class FC_Layer(nn.Module):
def __init__(self, n_hidden, target_size) -> None:
super().__init__()
self.fc = nn.Sequential(
nn.Linear(in_features=n_hidden, out_features=n_hidden*2),
nn.ReLU(),
nn.Linear(in_features=n_hidden*2, out_features=target_size)
)
def forward(self, x):
return self.fc(x)- GRU Model
class GRU_Model(nn.Module):
def __init__(self, vocab_len, target_size, device='cpu', emb_size=128, n_hidden=64) -> None:
super().__init__()
self.embedding_layer = Embedding_Layer(vocab_len, emb_size)
self.gru_layer = GRU_Layer(emb_size, n_hidden, device)
self.fc_layer = FC_Layer(n_hidden, target_size)
def forward(self, x):
emb_out = self.embedding_layer(x)
gru_out = self.gru_layer(emb_out)
fc_out = self.fc_layer(gru_out)
return fc_out
model = GRU_Model(vocab_len=len(vocab), target_size=len(vocab))!pip install torchinfo
import torchinfo
torchinfo.summary(
model=model,
input_size=(128, 14),
dtypes=[torch.long],
col_names=['input_size', 'output_size', 'num_params']
)
"""
===================================================================================================================
Layer (type:depth-idx) Input Shape Output Shape Param #
===================================================================================================================
GRU_Model [128, 14] [128, 2744] --
├─Embedding_Layer: 1-1 [128, 14] [128, 14, 128] --
│ └─Embedding: 2-1 [128, 14] [128, 14, 128] 351,232
├─GRU_Layer: 1-2 [128, 14, 128] [128, 64] --
│ └─GRU: 2-2 [14, 128, 128] [14, 128, 64] 811,008
├─FC_Layer: 1-3 [128, 64] [128, 2744] --
│ └─Sequential: 2-3 [128, 64] [128, 2744] --
│ │ └─Linear: 3-1 [128, 64] [128, 128] 8,320
│ │ └─ReLU: 3-2 [128, 128] [128, 128] --
│ │ └─Linear: 3-3 [128, 128] [128, 2744] 353,976
===================================================================================================================
Total params: 1,524,536
Trainable params: 1,524,536
Non-trainable params: 0
Total mult-adds (Units.GIGABYTES): 1.54
===================================================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 5.69
Params size (MB): 6.10
Estimated Total Size (MB): 11.81
===================================================================================================================
"""
Engine
- Early Stop
class EarlyStopper(object):
def __init__(self, num_trials, save_path):
self.num_trials = num_trials
self.trial_counter = 0
self.best_loss = np.inf
self.save_path = save_path
def is_continuable(self, model, loss):
if loss < self.best_loss:
self.best_loss = loss
self.trial_counter = 0
torch.save(model, self.save_path)
return True
elif self.trial_counter + 1 < self.num_trials:
self.trial_counter += 1
return True
else:
return False- Train Loop
def train_loop(model, dataloader, loss_fn, optimizer, device):
model.train()
epoch_loss = 0
for batch in tqdm(dataloader, desc='train loop', leave=False):
pred = model(batch['x'].to(device))
loss = loss_fn(pred, batch['y'].to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_loss /= len(dataloader)
return epoch_loss
Training
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = GRU_Model(vocab_len=len(vocab), target_size=len(vocab), device=device).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
early_stopper = EarlyStopper(num_trials=5, save_path='./trained_model.pth')
dt_train = GeneratorDataset(features=features, targets=targets)
dl_train = DataLoader(dataset=dt_train, batch_size=64, shuffle=True)
epochs = 500
list_loss = []
for i in tqdm(range(epochs), desc='epochs'):
train_loss = train_loop(
model=model,
dataloader=dl_train,
loss_fn=loss_fn,
optimizer=optimizer,
device=device
)
list_loss.append(train_loss)
if not early_stopper.is_continuable(model=model, loss_train_loss):
print(f'epoch: {i+1} >> best loss: {early_stopper.best_loss}')
breakimport seaborn as sns
sns.lineplot(list_loss)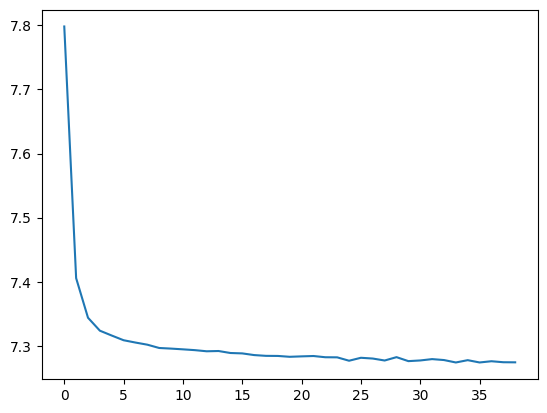
1-4. Generator
탐욕적 샘플링(Greedy Sampling)
- 자연어를 생성할 때, 가장 높은 확률을 가진 글자를 선택하여 생성한다.
@torch.no_grad()
def text_generation_by_greedy_sampling(model, vocab, current_word, sentence_size):
model.eval()
sentence = ''
sentence += current_word
init_encoded = vocab([current_word])
for _ in range(sentence_size):
encoded = init_encoded
encoded = [0] * (15 - len(encoded)) + encoded
encoded = np.array(encoded)
encoded = torch.tensor(encoded).view(1, -1).to(device)
pred = model(encoded)
char_no = pred.argmax(1).item()
init_encoded.append(char_no)
word = vocab.lookup_tokens([char_no])[0]
sentence = sentence + ' ' + word
return sentencebest_model = torch.load('./trained_model.pth').to(device)
text_generation_by_greedy_sampling(
model=best_model,
vocab=vocab,
current_word='you',
sentence_size=8
)
# 'you be be be be be be be be'
확률적 샘플링(Stochastic Sampling)
- 자연어를 생성할 때, 글자의 확률 분포에서 샘플링하여 생성한다.
def stochastic_sampling(pred, temp):
pred = pred / temp
m = np.max(pred)
ez = np.exp(pred - m)
proba_arr = ez / np.sum(ez)
return np.random.choice(np.arange(pred.shape[0]), p=proba_arr)@torch.no_grad()
def text_generation_by_stochastic_sampling(mode, voab, current_word, sentence_size, temp=None):
model.eval()
sentence = ''
sentence += current_sord
init_encoded = vocab([current_word])
for _ in range(sentence_size):
encoded = init_encoded
encoded = [0] * (14 - len(encoded)) + encoded
encoded = np.array(encoded)
encoded = torch.tensor(encoded).view(1, -1).to(device)
pred = model(encoded)
char_no = pred.argmax(1).item()
if temp is not None:
pred = pred.view(-1).to('cpu').numpy()
char_no = stochastic_sampling(pred, temp)
init_encoded.append(char_no)
word = vocab.lookup_tokens([char_no])[0]
sentence = sentence + ' ' + word
return sentencefor temp in [None, 0.5, 1.0, 1.5, 2.0]:
print(f'온도: {temp}')
sentence = text_generation_by_stochastic_sampling(
model=best_model,
vocab=vocab,
current_word='you',
sentence_size=10,
temp=temp
)
print(f'sentence: {sentence}')
"""
온도: None
sentence: you be be be be be be be be be be
온도: 0.5
sentence: you plan be be take be be be episode china .
온도: 1.0
sentence: you sunscreen mexicos technology sea client rescue table incel memo migrant
온도: 1.5
sentence: you make change franciscos grunt sarm man university rude shame explain
온도: 2.0
sentence: you jones stalk infinity slippery dream migrant liang photo racial option
"""
2. Seq2Seq
2-1. Seq2Seq
Encoder
- 인코더의 은닉 상태를 적절한 값으로 초기화한다.
- 매 시점 원문의 단어가 입력되면, 인코더는 이를 이용해 은닉 상태를 업데이트한다.
- 입력 시퀀스의 끝까지 이 과정을 반복하면 인코더의 최종 은닉 상태는 입력 시퀀스의 정보를 압축 요약한 정보를 담고 있다.
- 마지막 시점에서의 인코더 은닉 상태를 컨텍스트 벡터라고 하고, 이 값은 디코더로 넘어간다.
Decoder
- 디코더는 전달받은 컨텍스트 벡터로 은닉 상태를 초기화한다.
- 매 시점 바로 직전에 출력했던 단어를 입력으로 받아 은닉 상태를 업데이트하고, 이를 이용하여 다음 단어를 예측한다.
- 이 과정을 정해진 반복 횟수 또는 시퀀스 끝을 나타내는 <eos> 토큰이 나올 때까지 수행한다.
2-2. Seq2Seq of 번역
Setup
!pip install -U torchtext==0.15.2 kiwipiepyfrom google.colab import drive
drive.mount('/content/data')
DATA_PATH = ''import numpy as np
import torch
import torch.nn as nn
n_step = 5
n_hidden = 128
Data
- Data 생성
seq_data = [
['man', 'women'],
['black', 'white'],
['king', 'queen'],
['girl', 'boy'],
['up', 'down'],
['high', 'low']
]
np.array(seq_data).shape
# (6, 2)
batch_size = len(seq_data)
batch_size
# 6- Data Tokenization
char_arr = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz']
len(char_arr)
# 29- Data Dictionary
num_dic = {n: i for i, n in enumerate(char_arr)}
n_class = len(num_dic)
n_class
# 29
Train Data
- Train Data 생성
def make_batch():
input_batch, output_batch, target_batch = [], [], []
for seq in seq_data:
for i in range(len(seq)):
seq[i] = seq[i] + 'P' * (n_step - len(seq[i]))
input = [num_dic[n] for n in seq[0]]
output = [num_dic[n] for n in ('S' + seq[1])]
target = [num_dic[n] for n in (seq[1] + 'E')]
input_batch.append(np.eye(n_class)[input])
output_batch.append(np.eye(n_class)[output])
target_batch.append(target)
encoder_input_data = torch.FloatTensor(input_batch)
decoder_input_data = torch.FloatTensor(output_batch)
decoder_target_data = torch.LongTensor(target_batch)
return encoder_input_data, decoder_input_data, decoder_target_datainput_batch, output_batch, target_batch = make_batch()
input_batch.shape, output_batch.shape, target_batch.shape
# (torch.Size([6, 5, 29]), torch.Size([6, 6, 29]), torch.Size([6, 6]))
Seq2Seq Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.enc_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.dec_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.fc = nn.Linear(in_features=n_hidden, out_features=n_class)
def forward(self, enc_input, enc_hidden, dec_input):
enc_input = enc_input.transpose(0, 1)
dec_input = dec_input.transpose(0, 1)
_, enc_states = self.enc_cell(enc_input, enc_hidden)
outputs, _ = self.dec_cell(dec_input, enc_states)
_outputs = outputs.transpose(0, 1)
pred = self.fc(_outputs)
return pred
Training
model = Seq2Seq()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
input_batch, output_batch, target_batch = make_batch()
input_batch.shape, output_batch.shape, target_batch.shape
# (torch.Size([6, 5, 29]), torch.Size([6, 6, 29]), torch.Size([6, 6]))
for epoch in range(5000):
hidden = torch.zeros(1, batch_size, n_hidden)
output = model(input_batch, hidden, output_batch)
loss = 0
for i in range(0, len(target_batch)):
loss += criterion(output[i], target_batch[i])
optimizer.zero_grad()
loss.backward()
optimizer.step()
Test
def make_testbatch(input_word):
input_batch, output_batch = [], []
input_w = input_word + 'P' * (n_step - len(input_word))
input = [num_dic[n] for n in input_w]
output_w = 'S' + 'P' * n_step
output = [num_dic[n] for n in output_w]
input_batch = np.eye(n_class)[input]
output_batch = np.eye(n_class)[output]
return torch.FloatTensor(input_batch).unsqueeze(0), torch.FloatTensor(output_batch).unsqueeze(0)def translate(word):
input_batch, output_batch = make_testbatch(word)
hidden = torch.zeros(1, 1, n_hidden)
output = model(input_batch, hidden, output_batch)
predict = output.data.max(2, keepdim=True)[1]
decoded = [char_arr[i] for i in predict[0]]
end = decoded.index('E')
translated = ''.join(decoded[:end])
return translated.replace('P', '')
print('TEST')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('upp ->', translate('upp'))
"""
TEST
man -> women
mans -> women
king -> queen
black -> white
upp -> down
"""
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 47일차. 자연어 딥러닝 - Transformer & 자연어-이미지 멀티모달 - OCR(CRNN) & Vision - Generative Model (0) | 2025.03.19 |
|---|---|
| 46일차. 자연어 딥러닝 - Seq2Seq & Attention (0) | 2025.03.18 |
| 44일차. 자연어 딥러닝 - LSTM (0) | 2025.03.14 |
| 43일차. 자연어 딥러닝 - RNN (0) | 2025.03.13 |
| 42일차. 자연어 딥러닝 - RNN (0) | 2025.03.12 |



