더보기
29일 차 회고.
.코드가 점점 어려워져서 추가 공부를 해야할 것 같다.
1. PyTorch
1-1. Binary Classification
데이터 준비
# 데이터 생성
from sklearn.datasets import make_circles
n_samples = 1000
X, y = make_circles(
n_samples,
noise=0.03,
random_state=42
)
X.shape, y.shape
# ((1000, 2), (1000,))# 데이터 확인
import pandas as pd
circles = pd.DataFrame(
{
"X1": X[:, 0],
"X2": X[:, 1],
"label": y
}
)
circles.head()
circles['label'].value_counts()
import matplotlib.pyplot as plt
plt.scatter(
x=X[:, 0],
y=X[:, 1],
c=y,
cmap=plt.cm.RdYlBu
)
# 데이터 유형 변환
import torch
type(X), type(y)
# (numpy.ndarray, numpy.ndarray)
X = torch.from_numpy(X).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
type(X), type(y)
# (torch.Tensor, torch.Tensor)# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y
)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# (torch.Size([800, 2]),
# torch.Size([200, 2]),
# torch.Size([800]),
# torch.Size([200]))
모델 정의 - ModelV1
import torch
from torch import nn
device = 'cuda' if torch.cuda.is_available() else 'cpu
device
# 'cpu'# 모델 정의 - Model Version 1
class ModelV1(nn.Module):
def __init__(self, input_size=2, output_size=1) -> None:
super().__init__()
self.layer = nn.Linear(input_size, output_size)
def forward(Self, x):
out = self.layer(x)
return out
model_v1 = ModelV1().to(device)
model_v1
# ModelV1(
# (layer): Linear(in_features=2, out_features=1, bias=True)
# )!pip install torchinfo
import torchinfo
# Linear Regression Model: y = b + w1x1 + w2x2
input = (10, 2) # input -> (batch, feature)
torchinfo.summary(model_v1, input)
# ==========================================================================================
# Layer (type:depth-idx) Output Shape Param #
# ==========================================================================================
# ModelV1 [10, 1] --
# ├─Linear: 1-1 [10, 1] 3 # b, w1, w2
# ==========================================================================================
# Total params: 3
# Trainable params: 3
# Non-trainable params: 0
# Total mult-adds (Units.MEGABYTES): 0.00
# ==========================================================================================
# Input size (MB): 0.00
# Forward/backward pass size (MB): 0.00
# Params size (MB): 0.00
# Estimated Total Size (MB): 0.00
# ==========================================================================================
모델 학습 - ModelV1
# 정확도 함수
def accuracy_fn(y_true, y_pred):
correct = torch.eq(y_true, y_pred).sum().item()
acc = (correct / len(y_true)) * 100
return acc# Loss Function & Optimization
loss_fn = nn.BCEWithLogitsLoss()
model_v1 = ModelV1().to(device)
optimizer = torch.optim.SGD(
params=model_v1.parameters(),
lr=0.1
)torch.manual_seed(42)
epochs = 500
for epoch in range(epochs):
# Training Loop
model_v1.train()
y_pred = model_v1(X_train.to(device)).squeeze()
loss = loss_fn(y_pred, y_train.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
y_pred_prob = torch.round(torch.sigmoid(y_pred)
acc = accuracy_fn(y_true=y_train, y_pred=y_pred_prob.cpu())
# Testing Loop
model_v1.eval()
with torch.inference_mode():
y_pred = model_v1(X_test.to(device)).squeeze()
test_loss = loss_fn(y_pred, y_test.to(device))
y_pred_prob = torch.round(torch.sigmoid(y_pred))
test_acc = accuracy_fn(y_true=y_test, y_pred=y_pred_prob.cpu())
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%")
# Epoch: 0 | Loss: 0.72507, Accuracy: 50.38% | Test loss: 0.71475, Test acc: 51.50%
# Epoch: 100 | Loss: 0.71868, Accuracy: 50.88% | Test loss: 0.70917, Test acc: 52.00%
# Epoch: 200 | Loss: 0.71366, Accuracy: 51.00% | Test loss: 0.70493, Test acc: 51.50%
# Epoch: 300 | Loss: 0.70968, Accuracy: 50.75% | Test loss: 0.70169, Test acc: 51.00%
# Epoch: 400 | Loss: 0.70652, Accuracy: 50.62% | Test loss: 0.69921, Test acc: 51.50%from helper_functions import plot_predictions, plot_decision_boundary
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_v1, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_v1, X_test, y_test)
모델 정의 - ModelV2
# 모델 정의 - Model Version 2
class ModelV2(nn.Module):
def __init__(self, input_size=2, output_size=1, hidden_size=512) -> None:
super().__init__()
self.layer1 = nn.Linear(input_size, hidden_size)
self.layer2 = nn.Linear(hidden_size, hidden_size*2)
self.layer3 = nn.Linear(hidden_size*2, output_size)
def forward(Self, x):
out1 = self.layer(x)
out2 = self.layer(out1)
out3 = self.layer(out2)
return out3
model_v2 = ModelV2().to(device)
torchinfo.summary(model_v2, (10, 2))
# ==========================================================================================
# Layer (type:depth-idx) Output Shape Param #
# ==========================================================================================
# ModelV2 [10, 1] --
# ├─Linear: 1-1 [10, 512] 1,536
# ├─Linear: 1-2 [10, 1024] 525,312
# ├─Linear: 1-3 [10, 1] 1,025
# ==========================================================================================
# Total params: 527,873
# Trainable params: 527,873
# Non-trainable params: 0
# Total mult-adds (Units.MEGABYTES): 5.28
# ==========================================================================================
# Input size (MB): 0.00
# Forward/backward pass size (MB): 0.12
# Params size (MB): 2.11
# Estimated Total Size (MB): 2.23
# ==========================================================================================
모델 학습 - ModelV2
loss_fn = nn.BCEWithLogitsLoss()
model_v2 = ModelV2().to(device)
optimizer = torch.optim.SGD(
params=model_v2.parameters(), lr=0.001
)torch.manual_seed(42)
epochs = 500
for epoch in range(epochs):
# Training Loop
model_v2.train()
y_pred = model_v2(X_train.to(device)).squeeze()
loss = loss_fn(y_pred, y_train.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
y_pred_prob = torch.round(torch.sigmoid(y_pred)
acc = accuracy_fn(y_true=y_train, y_pred=y_pred_prob.cpu())
# Testing Loop
model_v2.eval()
with torch.inference_mode():
y_pred = model_v2(X_test.to(device)).squeeze()
test_loss = loss_fn(y_pred, y_test.to(device))
y_pred_prob = torch.round(torch.sigmoid(y_pred))
test_acc = accuracy_fn(y_true=y_test, y_pred=y_pred_prob.cpu())
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%")
# Epoch: 0 | Loss: 0.69603, Accuracy: 47.50% | Test loss: 0.69299, Test acc: 50.50%
# Epoch: 100 | Loss: 0.69359, Accuracy: 48.50% | Test loss: 0.69248, Test acc: 50.50%
# Epoch: 200 | Loss: 0.69319, Accuracy: 48.50% | Test loss: 0.69302, Test acc: 50.00%
# Epoch: 300 | Loss: 0.69311, Accuracy: 49.62% | Test loss: 0.69337, Test acc: 49.00%
# Epoch: 400 | Loss: 0.69309, Accuracy: 50.62% | Test loss: 0.69356, Test acc: 48.50%plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_v2, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_v2, X_test, y_test)
모델 정의 - ModelV3
# 모델 정의 - Model Version 3
class ModelV3(nn.Module):
def __init__(self, input_size=2, output_size=1, hidden_size=512) -> None:
super().__init__()
self.linear_relu_stack = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size)
)
def forward(Self, x):
out = self.linear_relu_stack(x)
return out
model_v3 = ModelV3().to(device)
torchinfo.summary(model_v3, (10, 2))
# ==========================================================================================
# Layer (type:depth-idx) Output Shape Param #
# ==========================================================================================
# ModelV3 [10, 1] --
# ├─Sequential: 1-1 [10, 1] --
# │ └─Linear: 2-1 [10, 512] 1,536
# │ └─ReLU: 2-2 [10, 512] --
# │ └─Linear: 2-3 [10, 512] 262,656
# │ └─ReLU: 2-4 [10, 512] --
# │ └─Linear: 2-5 [10, 1] 513
# ==========================================================================================
# Total params: 264,705
# Trainable params: 264,705
# Non-trainable params: 0
# Total mult-adds (Units.MEGABYTES): 2.65
# ==========================================================================================
# Input size (MB): 0.00
# Forward/backward pass size (MB): 0.08
# Params size (MB): 1.06
# Estimated Total Size (MB): 1.14
# ==========================================================================================
모델 학습 - ModelV3
loss_fn = nn.BCEWithLogitsLoss()
model_v3 = ModelV3().to(device)
optimizer = torch.optim.SGD(
params=model_v3.parameters(), lr=0.01
)torch.manual_seed(42)
epochs = 500
for epoch in range(epochs):
# Training Loop
model_v3.train()
y_pred = model_v3(X_train.to(device)).squeeze()
loss = loss_fn(y_pred, y_train.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
y_pred_prob = torch.round(torch.sigmoid(y_pred)
acc = accuracy_fn(y_true=y_train, y_pred=y_pred_prob.cpu())
# Testing Loop
model_v3.eval()
with torch.inference_mode():
y_pred = model_v3(X_test.to(device)).squeeze()
test_loss = loss_fn(y_pred, y_test.to(device))
y_pred_prob = torch.round(torch.sigmoid(y_pred))
test_acc = accuracy_fn(y_true=y_test, y_pred=y_pred_prob.cpu())
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%")
# Epoch: 0 | Loss: 0.69942, Accuracy: 50.00% | Test loss: 0.69884, Test acc: 50.00%
# Epoch: 100 | Loss: 0.68480, Accuracy: 53.25% | Test loss: 0.68500, Test acc: 55.50%
# Epoch: 200 | Loss: 0.67679, Accuracy: 62.50% | Test loss: 0.67734, Test acc: 64.50%
# Epoch: 300 | Loss: 0.66858, Accuracy: 70.25% | Test loss: 0.66915, Test acc: 71.00%
# Epoch: 400 | Loss: 0.65929, Accuracy: 81.88% | Test loss: 0.65971, Test acc: 84.00%plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_v3, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_v3, X_test, y_test)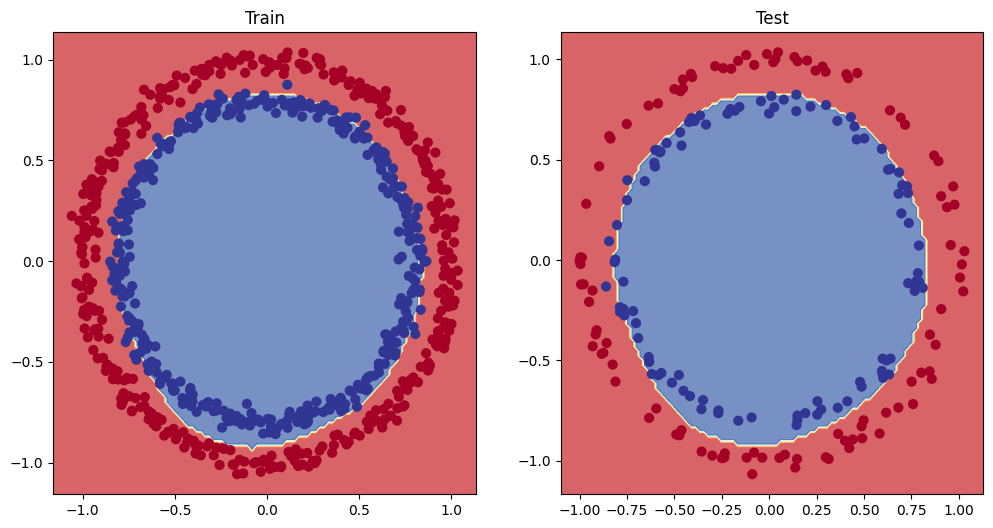
1-2. Multiclass Classification
데이터 준비
!pip install torchinfo
import torch
from torch import nn
import torchinfo
from torchvision import datasets
from torchvision.transforms import ToTensordevice = 'cuda' if torch.cuda.is_available() else 'cpu'
device
# 'cpu'# 데이터 생성
train_dataset = datasets.FashionMNIST(
root='download',
train=True,
download=True,
transform=ToTensor(),
)
test_dataset = datasets.FashionMNIST(
root='download',
train=False,
download=True,
transform=ToTensor(),
)# 데이터 확인
class_names = train_dataset.classes
class_names
# ['T-shirt/top',
# 'Trouser',
# 'Pullover',
# 'Dress',
# 'Coat',
# 'Sandal',
# 'Shirt',
# 'Sneaker',
# 'Bag',
# 'Ankle boot']import matplotlib.pyplot as plt
image, label = train_dataset[0]
plt.title(class_names[label])
plt.imshow(image.squeeze(), cmap='gray')
plt.axis(False)
plt.show()
DataLoader
# DataLoader
from torch.utils.data import DataLoader
batch_size = 32
train_dataloader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True
)
test_dataloader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=True
)# 데이터 확인
features, labels = next(iter(train_dataloader))
features.shape, labels.shape
# (torch.Size([32, 1, 28, 28]), torch.Size([32]))torch.manual_seed(42)
random_idx = torch.randint(0, len(features), size=(1,)).item()
img = features[random_idx]
label = labels[random_idx]
plt.title(class_names[label])
plt.imshow(img.squeeze(), cmap='gray')
plt.axis(False)
plt.show()
Model
class MultiClassificationModel(nn.Module):
def __init__(self, input_size, out_size, hidden_size=512) -> None:
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=input_size, out_features=hidden_size),
nn.ReLU(),
nn.Linear(in_features=input_size, out_features=hidden_size),
nn.ReLU(),
nn.Linear(in_features=input_size, out_features=hidden_size)
)
def forward(self, x):
return self.layer_stack(x)model = MultiClassificationModel(input_size=1*28*28, output_size=len(class_names)).to(device)
input_size = (10, 1, 28, 28)
torchinfo.summary(model, input_size)
# ==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
MultiClassificationModel [10, 10] --
├─Sequential: 1-1 [10, 10] --
│ └─Flatten: 2-1 [10, 784] --
│ └─Linear: 2-2 [10, 512] 401,920
│ └─ReLU: 2-3 [10, 512] --
│ └─Linear: 2-4 [10, 512] 262,656
│ └─ReLU: 2-5 [10, 512] --
│ └─Linear: 2-6 [10, 10] 5,130
==========================================================================================
Total params: 669,706
Trainable params: 669,706
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 6.70
==========================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 0.08
Params size (MB): 2.68
Estimated Total Size (MB): 2.79
==========================================================================================
모델 학습
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
params=model.parameters(),
lr=0.1
)from tqdm.auto import tqdm
form helper_functions import accuracy_fn
epochs = 100
for epoch in tqdm(range(epochs), desc="Epoch Loop", leave=True):
# Training Loop
model.train()
train_loss = 0
for batch, (feature, target) in tqdm(
enumerate(train_dataloader), desc="Training Loop", leave=False, total=len(train_dataloader)
):
pred = model(feature.to(device))
loss = loss_fn(pred, target.to(device))
train_loss += loss.cpu().item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss /= len(train_dataloader)
# Testing Loop
model.eval()
test_loss, test_acc = 0, 0
with torch.inference_mode():
for feature, target in tqdm(test_dataloader, desc="Testing Loop", leave=False):
pred = model(feature.to(device))
loss = loss_fn(pred, target.to(device))
test_loss += loss.cpu().item()
pred_prob = nn.Softmax(dim=1)(pred)
test_acc += accuracy_fn(y_true=target, y_pred=pred_prob.argmax(dim=1))
test_loss /= len(test_dataloader)
test_acc /= len(test_dataloader)
print(f"epoch: {epoch} | train loss: {train_loss:.2f} | test loss: {test_loss:.2f}, test acc: {test_acc:.2f}")
# epoch: 0 | train loss: 0.57 | test loss: 0.48, test acc: 82.45
# epoch: 1 | train loss: 0.39 | test loss: 0.40, test acc: 84.72
# epoch: 2 | train loss: 0.35 | test loss: 0.39, test acc: 84.91
# epoch: 3 | train loss: 0.32 | test loss: 0.36, test acc: 86.66
# epoch: 4 | train loss: 0.30 | test loss: 0.35, test acc: 87.32
# epoch: 5 | train loss: 0.29 | test loss: 0.35, test acc: 87.50
# epoch: 6 | train loss: 0.27 | test loss: 0.35, test acc: 86.99
# epoch: 7 | train loss: 0.26 | test loss: 0.32, test acc: 88.53
# epoch: 8 | train loss: 0.25 | test loss: 0.32, test acc: 88.40
# epoch: 9 | train loss: 0.24 | test loss: 0.31, test acc: 88.93def model_train(train_dataloader, model, loss_fn, optimizer):
model.train()
train_loss = 0
for feature, target in tqdm(train_dataloader, desc="Train Loop", leave=False):
# Training Model
pred = model(feature.to(device))
# Calculate Loss
loss = loss_fn(pred, target.to(device))
train_loss += loss.cpu().item()
# Loss Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss /= len(train_dataloader)
return train_loss
def model_validation(test_dataloader, model, loss_fn, accuracy_fn):
model.eval()
test_loss, test_accuracy = 0, 0
for feature, target in tqdm(test_dataloader, desc="Test Loop", leave=False):
pred = model(feature.to(device))
loss = loss_fn(pred, target.to(device))
test_loss += loss.cpu().item()
pred_prob = nn.Softmax(dim=1)(pred)
test_accuracy += accuracy_fn(y_true=target, y_pred=pred_prob.argmax(dim=1))
test_loss /= len(test_dataloader)
test_accuracy /= len(test_dataloader)
return test_loss, test_accuracy
def print_score(epoch, train_loss, test_loss, test_accuray):
print(f"epoch: {epoch}, train loss: {train_loss}, test loss: {test_loss}, test_accuray: {test_accuray}")
def training(train_dataloader, test_dataloader, model, loss_fn, optimizer, accuracy_fn, epochs=100):
train_losses, test_losses = [], []
for epoch in tqdm(range(epochs), desc="Epoch Loop", leave=True):
train_loss = model_train(train_dataloader, model, loss_fn, optimizer)
train_losses.append(train_loss)
test_loss, test_accuracy = model_validation(test_dataloader, model, loss_fn, accuracy_fn)
test_losses.append(test_loss)
print_score(epoch, train_loss, test_loss, test_accuray)
return train_losses, test_losses
loss_fn = nn.CrossEntropyLoss()
model = MultiClassificationModel(input_size=1*28*28, output_size=len(class_names)).to(device)
optimizer = torch.optim.SGD(
params=model.parameters(),
lr=0.1
)
train_losses, test_losses = training(train_dataloader, test_dataloader, model, loss_fn, optimizer, accuracy_fn, epochs=10)
# epoch: 0, train loss: 0.5734474489688873, test loss: 0.44452891667810873, test_accuray: 83.8158945686901
# epoch: 1, train loss: 0.39282068884770077, test loss: 0.45099429512461914, test_accuray: 84.11541533546325
# epoch: 2, train loss: 0.3476636857171853, test loss: 0.40911830771274077, test_accuray: 84.39496805111821
# epoch: 3, train loss: 0.322720076328516, test loss: 0.3643986723555353, test_accuray: 86.45167731629392
# epoch: 4, train loss: 0.3020094704369704, test loss: 0.3604937405727161, test_accuray: 86.9408945686901
# epoch: 5, train loss: 0.2855522959669431, test loss: 0.338384105362736, test_accuray: 87.48003194888179
# epoch: 6, train loss: 0.27160963269074756, test loss: 0.3305092181284397, test_accuray: 87.71964856230032
# epoch: 7, train loss: 0.25890137823124726, test loss: 0.33659028833190474, test_accuray: 88.0591054313099
# epoch: 8, train loss: 0.24900290319124857, test loss: 0.3161588677297385, test_accuray: 88.62819488817891
# epoch: 9, train loss: 0.23878132457832496, test loss: 0.3140233466133904, test_accuray: 88.81789137380191
모델 평가
plt.plot(train_losses, label="Train Loss")
plt.plot(test_losses, label="Train Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()
모델 예측
import random
test_samples = []
test_labels = []
for sample, label in random.sample(list(test_dataset), k=9):
test_samples.append(sample)
test_labels.append(label)plt.figure(figsize=(12, 9))
nrows = 3
ncols = 3
for i, sample in enumerate(test_samples):
plt.subplot(nrows, ncols, i+1)
plt.imshow(sample.permute(1, 2, 0), cmap='gray')
plt.axis(False)
pred = model(sample.unsqueeze(dim=0).to(device))
pred = nn.Softmax(dim=1)(pred).argmax(dim=1)
pred_label = class_names[pred.cpu().item()]
truth_label = class_names[test_labels[i]]
title = f"Pred: {pred_label} | Truth: {truth_label}"
if pred_label == truth_label:
plt.title(title, c='g')
else:
plt.title(title, c='r')
plt.show()
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 31일차. Deep Learning - Vision(Image Preprocessing & CNN) (0) | 2025.02.24 |
|---|---|
| 30일차. PyTorch - Multiclass Classification (0) | 2025.02.21 |
| 28일차. PyTorch - Model Layers & Regression (0) | 2025.02.19 |
| 27일차. PyTorch - Dataset (0) | 2025.02.18 |
| 26일차. Deep Learning & PyTorch - Tensor (0) | 2025.02.17 |



