더보기
28일 차 회고.
두 번째 단위 프로젝트 팀 편성이 나왔다. 이번 단위는 데이터 분석과 머신러닝/딥러닝이었는데 내용이 어려웠어서 잘할 수 있을지 걱정이 된다.
1. PyTorch
1-1. Model Layers and Automatic Differentiation
Neural Network
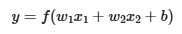
- 가중치(weight): 네트워크의 출력이 예상 출력 값에 얼마나 근접하는지에 영향을 미친다.
- 편향(bias): 활성 함수의 출력과 의도한 출력 간의 차이를 나타낸다.
Import Modules
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
Get a Hardware Device for Training
device = 'cuda' if torch.cuda.is_available() else 'cpu'
Define the Class
# Neural Network Version 1
class NeuralNetworkV1(nn.Module): # nn.Module 상속
def __init__(self) -> None:
super().__init__()
self.flatten = nn.Flatten()
self.linear_layer1 = nn.Linear(1*28*28, 512)
self.fnc_layer1 = nn.ReLU()
self.linear_layer2 = nn.Linear(512, 512)
self.fnc_layer2 = nn.ReLU()
self.linear_layer3 = nn.Linear(512, 10)
self.fnc_layer3 = nn.ReLU()
def forward(self, features):
# features - (batch, color, row, column)
out_flatten = self.flatten(features)
out_linear_layer1 = self.linear_layer1(out_flatten)
out_fnc_layer1 = self.fnc_layer1(out_linear_layer1)
out_linear_layer2 = self.linear_layer2(out_fnc_layer1)
out_fnc_layer2 = self.fnc_layer2(out_linear_layer2)
out_linear_layer3 = self.linear_layer3(out_fnc_layer2)
out_fnc_layer3 = self.fnc_layer3(out_linear_layer3)
return out_fnc_layer3
model_v1 = NeuralNetworkV1().to(device)
model_v1
# NeuralNetworkV1(
# (flatten): Flatten(start_dim=1, end_dim=-1)
# (linear_layer1): Linear(in_features=784, out_features=512, bias=True)
# (fnc_layer1): ReLU()
# (linear_layer2): Linear(in_features=512, out_features=512, bias=True)
# (fnc_layer2): ReLU()
# (linear_layer3): Linear(in_features=512, out_features=10, bias=True)
# (fnc_layer3): ReLU()
# )
features = torch.rand(5, 1, 28, 28).to(device)
features.shape
# torch.Size([5, 1, 28, 28]) # torch.Size([batch, color, row, column])
predict_v1 = model_v1(features) # forward method 실행
predict_v1.shape
# features: torch.Size([5, 1, 28, 28])
# out_flatten: torch.Size([5, 784])
# out_linear_layer1: torch.Size([5, 512])
# out_linear_layer2: torch.Size([5, 512])
# out_linear_layer3: torch.Size([5, 10])
# torch.Size([5, 10])
predict_v1
# tensor([[0.0000, 0.0000, 0.0043, 0.0344, 0.0000, 0.1526, 0.0000, 0.0480, 0.0000,
# 0.0000],
# [0.0000, 0.0000, 0.0263, 0.0289, 0.0000, 0.1086, 0.0000, 0.0619, 0.0000,
# 0.0000],
# [0.0000, 0.0000, 0.0155, 0.0000, 0.0000, 0.1142, 0.0000, 0.0363, 0.0000,
# 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1382, 0.0000, 0.0426, 0.0000,
# 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1153, 0.0000, 0.0631, 0.0000,
# 0.0000]], grad_fn=<ReluBackward0>)
pred_proba = nn.Sortmax(dim=1)(predict_v1)
pred_proba.shape
# torch.Size([5, 10])
pred_proba
# tensor([[0.0975, 0.0975, 0.0979, 0.1009, 0.0975, 0.1136, 0.0975, 0.1023, 0.0975,
# 0.0975],
# [0.0977, 0.0977, 0.1003, 0.1006, 0.0977, 0.1089, 0.0977, 0.1039, 0.0977,
# 0.0977],
# [0.0983, 0.0983, 0.0998, 0.0983, 0.0983, 0.1102, 0.0983, 0.1019, 0.0983,
# 0.0983],
# [0.0981, 0.0981, 0.0981, 0.0981, 0.0981, 0.1127, 0.0981, 0.1024, 0.0981,
# 0.0981],
# [0.0982, 0.0982, 0.0982, 0.0982, 0.0982, 0.1102, 0.0982, 0.1046, 0.0982,
# 0.0982]], grad_fn=<SoftmaxBackward0>)
y_pred = pred_proba.argmax(dim=1)
y_pred
# tensor([5, 5, 5, 5, 5])# Neural Network Version 2
class NeuralNetworkV2(nn.Module):
def __init__(self, input_size:int, output_size:int, hidden_size:int=512) -> None:
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size),
nn.ReLU()
)
def forward(self, features):
out_flatten = self.flatten(features)
out = self.linear_relu_stack(out_flatten)
return out
model_v2 = NeuralNetworkV2(28*28, 10).to(device)
model_v2
# NeuralNetworkV2(
# (flatten): Flatten(start_dim=1, end_dim=-1)
# (linear_relu_stack): Sequential(
# (0): Linear(in_features=784, out_features=512, bias=True)
# (1): ReLU()
# (2): Linear(in_features=512, out_features=512, bias=True)
# (3): ReLU()
# (4): Linear(in_features=512, out_features=10, bias=True)
# (5): ReLU()
# )
# )
model_v2.linear_relu_stack[0]
# Linear(in_features=784, out_features=512, bias=True)
model_v2.linear_relu_stack[0].weight.shape
# torch.Size([512, 784])
model_v2.linear_relu_stack[0].bias.shape
# torch.Size([512])
1-2. Pytorch Workflow with Regression
데이터 준비
import torch
from torch import nn
import matplotlib.pyplot as plt # CPU에서 작동
plt.ion()
torch.__version__ # PyTorch 버전 확인
# '2.5.1+cu124'# 데이터 생성
# Linear Regression: y = weight * X + bias
weight = 0.7
bias = 0.3
start = 0
end = 1
step = 0.02
X = torch.arange(start, end, step).unsqueeze(dim=1)
X.shape
# torch.Size([50, 1])
y = weight * X + bias
y.shape
# torch.Size([50, 1])
X[:5], y[:5]
# (tensor([[0.0000],
# [0.0200],
# [0.0400],
# [0.0600],
# [0.0800]]),
# tensor([[0.3000],
# [0.3140],
# [0.3280],
# [0.3420],
# [0.3560]]))# 데이터 분리
train_split = int(0.8 * len(X))
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
len(X_train), len(y_train), len(X_test), len(y_test)
# (40, 40, 10, 10)# 데이터 확인
def plot_predictions(
train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=None):
plt.figure(figsize=(10, 7))
plt.scatter(train_data, train_labels, c='b', s=4, label="Training Data")
plt.scatter(test_data, test_labels, c='g', s=4, label="Testing Data")
if predictions is not None:
# GPU로 돌릴 경우, .cpu() 추가
plt.scatter(test_data, predictions.cpu(), c='r', s=4, label="Predictions")
plt.legend(prop={'size': 14})
plt.show()
plot_predictions()
모델링 정의
# 모델 정의
class LinearRegressionModel(nn.Module):
def __init__(self) -> None:
super().__init__()
self.weights = nn.Parameter(
torch.randn(1, dtype=torch.float),
requires_grad=True
)
self.bias = nn.Parameter(
torch.randn(1, dtype=torch.float),
requires_grad=True
)
def forward(self, x):
pred = self.weights * X + self.bias
return pred
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(42)
model = LinearRegressionModel().to(device)
model
# LinearRegressionModel()
list(model.parameters())
# [Parameter containing:
# tensor([0.3367], requires_grad=True),
# Parameter containing:
# tensor([0.1288], requires_grad=True)]
model.state_dict()
# OrderedDict([('weights', tensor([0.3367])), ('bias', tensor([0.1288]))])# 학습하기 전 모델 예측
with torch.inference_mode(): # with torch.no_grad()
y_preds = model(X_test.to(device)) # GPU로 돌릴 경우, to(device) 추가
plot_predictions(predictions=y_preds)
모델 학습
# Loss Function
"""
Regression Tasks
- nn.MSELoss: Mean Square Error
- nn.L1Loss: Mean Absolute Error
Binary Classification Tasks
- nn.BCELoss: Binary Cross Entropy
- nn.BCEWithLogitsLoss: nn.BCELoss + nn.Sigmoid
Multi Classification Tasks
- nn.CrossEntropyLoss: nn.NLLLoss + nn.LogSoftmax
"""
loss_fn = nn.L1Loss()# Optimization
"""
- SGD
- Adam
"""
optimizer = torch.optim.SGD(
params=model.parameters(),
lr=0.01
)# 학습
torch.manual_seed(42)
epochs = 100
train_loss_values = []
test_loss_values = []
epoch_count = []
for epoch in range(epochs):
# Training Loop
model.train()
y_pred = model(X_train.to(device))
loss = loss_fn(y_pred, y_train.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Testing Loop
model.eval()
with torch.inference_mode():
test_pred = model(X_test.to(device))
test_loss = loss_fn(test_pred, y_test.type(torch.float).to(device))
if epoch % 10 == 0:
epoch_count.append(epoch)
train_loss_values.append(loss.detach().cpu().numpy())
test_loss_values.append(test_loss.detach().cpu().numpy())
print(f"Epoch: {epoch} | MAE Train Loss: {loss} | MAE Test Loss: {test_loss}")
# Epoch: 0 | MAE Train Loss: 0.31288135051727295 | MAE Test Loss: 0.48106518387794495
# Epoch: 10 | MAE Train Loss: 0.1976713389158249 | MAE Test Loss: 0.3463551998138428
# Epoch: 20 | MAE Train Loss: 0.08908725529909134 | MAE Test Loss: 0.21729658544063568
# Epoch: 30 | MAE Train Loss: 0.0531485341489315 | MAE Test Loss: 0.14464019238948822
# Epoch: 40 | MAE Train Loss: 0.04543796926736832 | MAE Test Loss: 0.11360953003168106
# Epoch: 50 | MAE Train Loss: 0.04167863354086876 | MAE Test Loss: 0.09919948130846024
# Epoch: 60 | MAE Train Loss: 0.03818932920694351 | MAE Test Loss: 0.08886633068323135
# Epoch: 70 | MAE Train Loss: 0.03476089984178543 | MAE Test Loss: 0.0805937647819519
# Epoch: 80 | MAE Train Loss: 0.03132382780313492 | MAE Test Loss: 0.07232122868299484
# Epoch: 90 | MAE Train Loss: 0.02788739837706089 | MAE Test Loss: 0.06473556160926819# 학습 결과
plt.plot(epoch_count, train_loss_values, label="Train Loss")
plt.plot(epoch_count, test_loss_values, label="Test Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()
model.state_dict()
# OrderedDict([('weights', tensor([0.5784])), ('bias', tensor([0.3513]))])
모델 평가
model.eval()
with torch.inference_mode():
y_pred = model(X_test.to(device))
plot_predictions(predictions=y_pred)
모델 저장
# Save Model
from pathlib import Path
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
MODEL_NAME = "01_pytorch_workflow_model.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
MODEL_SAVE_PATH
# PosixPath('models/01_pytorch_workflow_model.pth')
torch.save(obj=model.state_dict(), f=MODEL_SAVE_PATH)# Load Model
load_model = LinearRegressionMode().to(device)
load_model.load_state_dict(
torch.load(model_save_path)
)
load_model.eval()
with torch.inference_mode():
y_pred = load_model(X_test.to(device))
plot_predictions(predictions=y_pred)
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 30일차. PyTorch - Multiclass Classification (0) | 2025.02.21 |
|---|---|
| 29일차. PyTorch - Binary Classification & Multiclass Classification (0) | 2025.02.20 |
| 27일차. PyTorch - Dataset (0) | 2025.02.18 |
| 26일차. Deep Learning & PyTorch - Tensor (0) | 2025.02.17 |
| 25일차. AutoML & XAI & Pipeline (0) | 2025.02.14 |



