더보기
25일 차 회고.
내가 해야 할 일
1. ADsP 공부 - 2.22 시험
2. 데이터 분석 공부 - 데이터 분석 프로세스 정리
3. 블로그 정리 - 수정 및 추가(19, 20일 차)
4. 데이콘 참여 - 3.31 마감
1. AutoML
1-1. AutoML
AutoML은 기계 학습을 데이터에 적용하는 프로세스를 자동화한다. 데이터 세트가 있는 경우, AutoML을 실행하여 데이터 변환, 머신러닝 알고리즘, 하이퍼 파라미터에 대해 최상의 모델을 선택할 수 있다.
Machine Learning 과정
- 데이터 전처리
- 데이터 수집
- 데이터 가공
- 데이터 이해
- 특징 추출
- 결측값 및 누락값 처리
- 모델 생성
- 특징량 엔지니어링
- 학습에 의한 모델 구축
- 파라미터 튜닝 모델 평가
- 모델 평가
- 모델 활용
- 시스템에 삽입 운용
- 예측, 최적화 실행
Machine Learning 알고리즘
- 지도학습(Supervised Learning)
- 회귀(Regression)
- 분류(Classification)
- 비지도학습(Unsupervised Learning)
- 차원 축소(Dimensionality Reduction)
- 클러스터링(Clustering)
- 강화학습(Reinforcement Learning)
AutoML 작동 방식
- 문제 정의
- 데이터 수집
- 데이터 전처리
- 모델 학습
- 모델평
1-2. PyCaret
PyCaret 설치
!pip install --upgrade pandas==2.2.2 matplotlib==3.8.0
!pip install pycaret[full]
import pycaret
pycaret.__version__ # '3.3.2'
PyCaret Tutorial
# Load Dataset
from pycaret.datasets import get_data
dataset = get_data('credit')
train = dataset.sample(frac=0.95, random_state=786)
test = dataset.drop(train.index)
train.reset_index(inplace=True, drop=True)
test.reset_index(inplace=True, drop=True)# Setup
from pycaret.classification import *
exp_clf = setup(data = train, target = 'default', session_id=123) # session_id: seed 고정# Compare Models
best_model = compare_models()
# Analyze Model - Confusion Matrix
plot_model(best_model, plot = 'confusion_matrix')
# Analyze Model - AUC
plot_model(best_model, plot = 'auc')
# Analyze Model - Feature Importance
plot_model(best_model, plot = 'feature')
# Analyze Model
evaluate_model(best_model)
2. XAI(Explainable Artificial Intelligence)
2-1. XAI
XAI는 인공지능의 행위와 도출한 결과를 사람이 이해할 수 있는 형태로 설명하는 방법론과 분야를 말한다. 이를 통해 인공지능의 불확실성을 해소하고 신뢰성을 높이는 역할을 한다.
2-2. SHAP vs. SAGE

SHAP
SHAP는 각 특성이 모델의 예측에 기여한 정도를 계산한다.
SAGE
SAGE는 각 특성이 모델 성능에 영향을 끼친 정도를 계산한다.
2-3. 데이터 준비
# Load Dataset
import numpy as np
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
cols = ["age", "sibsp", "parch", "fare"]
features = df[cols]
target = df["survived"]# Data Encoding
from sklearn.preprocessing import OneHotEncoder
cols = ["pclass", "sex", "embarked"]
enc = OneHotEncoder(handle_unknown='ignore')
tmp = pd.DataFrame(
enc.fit_transform(df[cols]).toarray(),
columns = enc.get_feature_names_out()
)
features = pd.concat([features,tmp], axis=1)#
features.age = features.age.fillna(features.age.median())# Data Scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
features = pd.DataFrame(
scaler.fit_transform(features),
columns = features.columns
)# Split Dataset
from sklearn.model_selection import KFold, cross_val_score
from sklearn.model_selection import train_test_split
random_state=42
X_tr, X_te, y_tr, y_te = train_test_split(
features, target, test_size=0.20,
random_state=random_state)
X_tr.shape, X_te.shape # ((712, 13), (179, 13))
2-4 SAGE(Shapley Additive Global importancE)
# Learning
from lightgbm import LGBMClassifier, plot_importance
model = LGBMClassifier(random_state=random_state).fit(X_tr, y_tr)# Evaluation
from sklearn.metrics import roc_auc_score
pred = model.predict_proba(X_te)[:,1]
roc_auc_score(y_te, pred)import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize = (15, 10))
plot_importance(model, ax=ax) # 수치형 / 범주형 데이터 분리하여 판단
plt.show()
2-5. SHAP(SHapley Additive exPlanations)
!pip install shap
!pip install scikit-image
import shap
import skimage
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_te) # shap_values: 각 특성의 중요도
force_plot
shap.initjs()
shap.force_plot(explainer.expected_value,shap_values[0,:],X_te.iloc[0,:])
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values, X_te)
summary_plot
- 전체 데이터의 영향력을 간단하게 시각화하여 보여준다.
- 색이 섞인 경우, 전처리가 필요하다.
shap.summary_plot(shap_values, X_te) # 수치형 / 범주형 데이터 분리하여 판단
dependence_plot
- 특정 변수에 대한 영향도를 파악한다.
shap.dependence_plot("age", shap_values, X_te, interaction_index="auto")
3. Pipeline
3-1. Load Dataset
!pip install --upgrade joblib==1.1.0
!pip install --upgrade scikit-learn==1.1.3
!pip install mglearn
import logging
logging.getLogger('matplotlib.font_manager').setLevel(logging.ERROR)
from sklearn.svm import SVC
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
cancer = load_breast_cancer()
X_tr, X_te, y_tr, y_te = train_test_split(
cancer.data, cancer.target, random_state=0
)
3-2. Without Pipeline
Scaling
scaler = MinMaxScaler().fit(X_tr)
X_tr_scaled = scaler.transform(X_tr)
X_te_scaled = scaler.transform(X_te)
SVC
svm = SVC()
svm.fit(X_tr_scaled, y_tr)
svm.score(X_te_scaled, y_te) # 0.972027972027972
GridSearchCV
from sklearn.model_selection import GridSearchCV
param_grid = {
'C': [0.001, 0.01, 0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1, 10, 100]
}
grid = GridSearchCV(SVC(), param_grid=param_grid, cv=5)
grid.fit(X_tr_scaled, y_tr)
grid.best_score_ # 0.9812311901504789
grid.best_params_ # {'C': 1, 'gamma': 1}
grid.score(X_te_scaled, y_te) # 0.972027972027972
결과 분석
- MinMaxScaler가 training dataset의 모든 데이터를 사용하였다.
import mglearn
mglearn.plots.plot_improper_processing()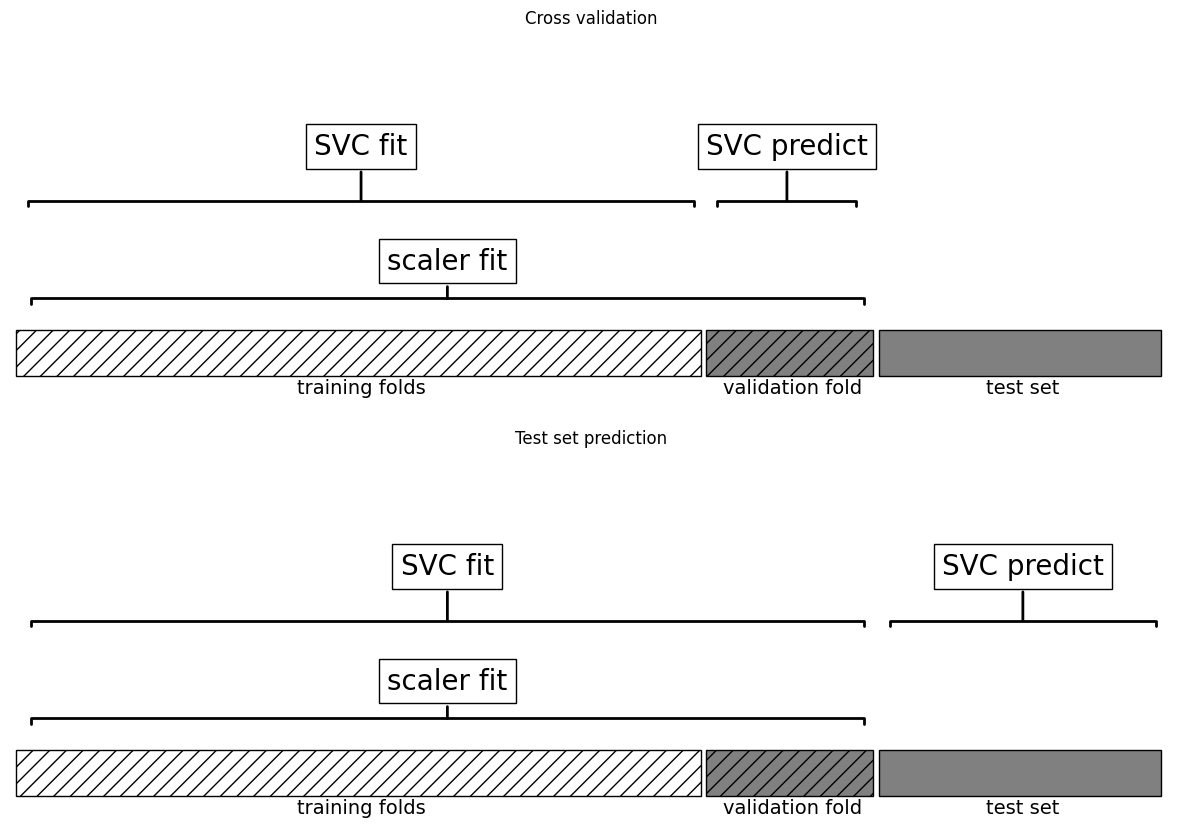
3-3. With Pipeline
SVC with Scaling
from sklearn.pipeline import Pipeline
pipe = Pipeline([
('scaler', MinMaxScaler()), # scaling model -> features 크기 조절
('svm', SVC()) # training model -> target 예측
])
pipe.fit(X_tr, y_tr)
pipe.score(X_te, y_te) # 0.972027972027972
GridSearchCV
param_grid = {
'svm__C': [0.001, 0.01, 0.1, 1, 10, 100],
'svm__gamma': [0.001, 0.01, 0.1, 1, 10, 100]
}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=5)
grid.fit(X_tr, y_tr)
grid.best_score_ # 0.9812311901504789
grid.best_params_ # {'svm__C': 1, 'svm__gamma': 1}
grid.score(X_te, y_te) # 0.972027972027972
결과 분석
mglearn.plots.plot_proper_processing()
3-4. Pipeline 심화
데이터 로드
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
url = "http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data"
abalone = pd.read_csv(
url,
sep=",",
names = ['sex', 'length', 'diameter', 'height',
'whole_weight', 'shucked_weight', 'viscera_weight',
'shell_weight', 'rings'],
header = None)
abalone.head()
숫자형 변수 전처리 pipeline
num_features = ["length", "whole_weight"]
num_transformer = Pipeline(
steps = [("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler())]
)
범주형 변수 전처리 pipeline
cat_features = ["sex"]
cat_transformer = OneHotEncoder(handle_unknown="ignore")
전처리 pipeline 합치기
preprocessor = ColumnTransformer(
transformers = [
("num", num_transformer, num_features),
("cat", cat_transformer, cat_features)
]
)
전체 pipeline
pipe = Pipeline(
steps = [("preporcessor", preprocessor), ("regressor", LinearRegression())]
)
pipe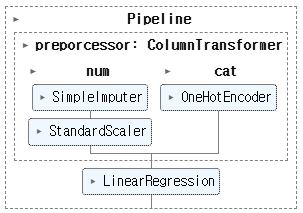
데이터 분리
X = abalone[["length", "whole_weight", "sex"]]
y = abalone["rings"]
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.2, random_state=42)
학습
from sklearn import set_config
set_config(display='diagram')
pipe.fit(X_tr, y_tr)from sklearn.metrics import mean_absolute_percentage_error
y_pred = pipe.predict(X_te)
mean_absolute_percentage_error(y_te, y_pred) # 0.1853230655055772
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 27일차. PyTorch - Dataset (0) | 2025.02.18 |
|---|---|
| 26일차. Deep Learning & PyTorch - Tensor (0) | 2025.02.17 |
| 24일차. Imbalanced Data & Cross Validation (0) | 2025.02.13 |
| 23일차. Unsupervised Learning (0) | 2025.02.12 |
| 22일차. Supervised Learning - Classification & Ensemble & HPO (0) | 2025.02.11 |



