26일 차 회고.
오늘 정기 상담을 진행했는데, 대회에 참여해 보는 것이 좋겠다는 말을 들었다. 아무래도 대회나 수상 경험이 하나도 없어서 그 부분을 채우는 것이 필수일 것 같다. 그리고 포트폴리오를 조금씩 만들어나가야 할 것 같다.
1. Deep Learning
1-1. 인공지능(Artificial Intelligence)
인공지능
인공지능은 사람의 지능을 만들기 위한 시스템이나 프로그램을 말한다. 이는 머신러닝에 포함되는 기술이다.
1-2. 인공신경망
노드(Node)
- 각각의 신경 단위에서 많은 입력들을 조합해서 하나의 출력값으로 배출한다.
- 비선형 변환(활성 함수)을 통해 다음 노드에 전달한다.
피드 포워드(Feed-Forward) 신경망
- 입력에서 출력으로 이어지는 과정이 한 방향으로 흘러 순환이 없는 신경망
인공 뉴런(퍼셉트론)
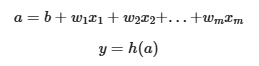
- w(weight): 가중치
- b(bias): 편향
- a: 다중 선형 회귀 모델
- h(): 활성 함수(Activation Function)
1-3. 딥러닝(Deep Learning)
딥러닝(Deep Learning)

- 딥러닝은 인공신경망을 다양하게 쌓은 것이다.
- 머신러닝이 처리하기 어려운 비정형 데이터를 더 잘 처리한다.
- 학습을 위해 상당히 많은 양의 데이터를 필요로 한다.
- 계산이 복잡하고 수행 시간이 오래 걸린다.
1-4. 손실 함수(Loss Function)
손실 함수(Loss Function)
- 손실 함수는 출력값과 정답과의 차이를 의미한다.
- 인공신경망이 학습할 수 있도록 해주는 지표
- 손실값이 최소화되도록 하는 가중치와 편향을 찾는 것이 학습의 목표이다.
회귀(Regression) 손실 함수
- MSE(Mean Squared Error)
- L2 Loss
- 이상치에 민감하다.
- MAE(Mean Absolute Error)
- L1 Loss
- 이상치에 강하다.
다중 분류(Multiclass Classification) 손실 함수
- CE(Cross Entropy)
- 예측 확률이 실제값과 비슷한 정도를 수치화한다.
이진 분류(Binary Classification) 손실 함수
- BCE(Binary Cross Entropy)
1-5. 경사하강법(Gradient Descent)
경사하강법(Gradient Descent)
- 모델이 잘 학습할 수 있도록 기울기를 통해 모델의 파라미터를 조정한다.
- 예측과 실제값을 비교하여 손실을 구한다.
- 손실이 작아지는 방향으로 파라미터를 조정한다.
- 위 과정을 반복한다.
학습률(Learning Rate)
- 파라미터를 업데이트하는 정도를 조절하기 위한 값
1-6. Optimizer
SGD(확률적 경사 하강법)
- 임의로 추출한 일부 데이터를 사용해 더 빨리, 자주 업데이트한다.
Momentum
- 기존 업데이트에 사용했던 경사의 일정 비율을 남겨서 현재의 경사와 더하여 업데이트한다.
Adagrad
- 각 파라미터의 업데이트 정도에 따라 학습률의 크기를 다르게 한다.
RMSProp
- 이전 업데이트 맥락을 통해 학습률을 조정하여 최신 기울기를 더 크게 반영한다.
Adam
- Momentum과 RMSProp 장점을 함께 사용한다.
1-7. 역전파(Back-Propagation)
역전파(Back-Propagation)
- 손실값을 구해 이 손실에 관여하는 가중치들을 손실이 작아지는 방향으로 수정한다.
- 파라미터를 업데이트할 때 필요한 손실에 대한 기울기를 역방향으로 업데이트한다.
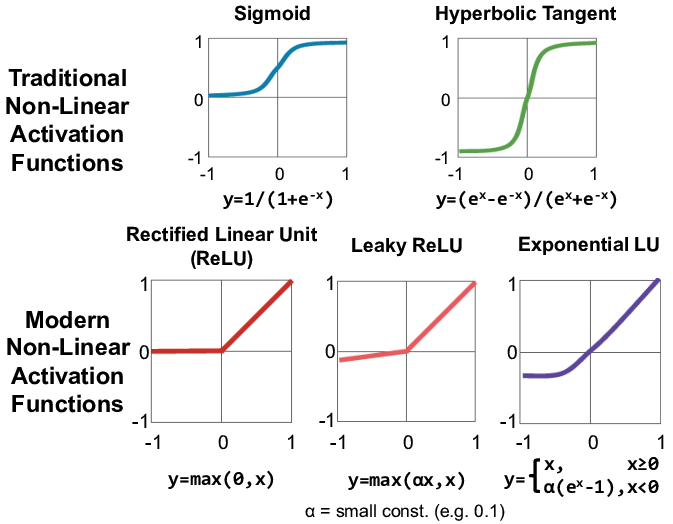
1-8. 활성 함수(Activation Function)
기울기 소실(Vanishing Gradient)
- 딥러닝이 복잡해질수록 기울기 소실이 발생한다.
- ReLU를 통해 기울기 소실 문제를 해결할 수 있다.
- ReLU는 수식이 단순하여 연산 속도가 빠르다.
활성 함수(Activation Function)
1-9. 배치(Batch)
배치(Batch)
- GPU의 병렬 연산 기능을 최대한 효율적으로 사용하기 위해 한 번에 여러 개의 데이터를 묶어서 입력한다.
BGD(Batch Gradient Descent)
- 전체 데이터에 대해 error gradient를 계산하기 때문에 optimal로 수렴이 안정적이다.
- local optimal 상태가 되면 빠져나오기 힘들다.
SGD(Stochastic Gradient Descent)
- shooting이 일어나기 때문에 local optimal에 빠질 위험이 적다.
- global optimal을 찾지 못할 가능성이 있다.
Mini-Batch Gradient Descent
- BGD보다 local optimal에 빠질 위험이 적다.
- batch size를 설정해야 한다.
Epoch
- 학습 데이터의 학습 단위

Internal Covariant Shift
- batch 단위로 학습을 하면 학습 과정에서 계층 별로 입력의 데이터 분포가 달라진다.
- 각 계층에서 입력으로 feature를 받고 해당 feature는 convolution 또는 fully connected 연산을 거친 뒤 activation function을 적용할 경우, 데이터 간 분포가 달라질 수 있다.
Batch Normalization
- 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화한다.
2. PyTorch
2-1. Tensor
Tensor 생성
import numpy as np
import torch# Directly from data
data = [
[1, 2], [3, 4], [5, 6]
]
tensor_data = torch.tensor(data)
tensor_data
# tensor([[1, 2],
# [3, 4],
# [5, 6]])
type(tensor_data)
# torch.Tensor
tensor_data.shape
# torch.Size([3, 2])
type(tensor_data.shape)
# torch.Size# From a Numpy array
np_data = np.array(data)
tensor_arr = torch.from_numpy(np_data)
tensor_arr
# tensor([[1, 2],
# [3, 4],
# [5, 6]])
type(tensor_arr)
# torch.Tensorprint(f"Numpy: {np_data}")
print(f"Pytorch: {tensor_arr}")
# Numpy: [[1 2]
# [3 4]
# [5 6]]
# Pytorch: tensor([[1, 2],
# [3, 4],
# [5, 6]])
np.multiply(np_data, 2, out=np_data)
print(f"Numpy: {np_data}")
print(f"Pytorch: {tensor_arr}")
# Numpy: [[ 2 4]
# [ 6 8]
# [10 12]]
# Pytorch: tensor([[ 2, 4],
# [ 6, 8],
# [10, 12]])# From another Tensor
tensor_ones = torch.ones_like(tensor_arr)
tensor_ones
# tensor([[1, 1],
# [1, 1],
# [1, 1]])
type(tensor_ones)
# torch.Tensortensor_rand = torch.rand_like(tensor_arr, dtype=torch.float)
tensor_rand
# tensor([[0.0672, 0.8087],
# [0.9182, 0.7752],
# [0.5233, 0.7272]])
type(tensor_rand)
# torch.Tensor# With random or constant values
shape = (2, 3)
rand_tensor = torch.rand(shape)
rand_tensor
# tensor([[0.6630, 0.8727, 0.8135],
# [0.4249, 0.8526, 0.1308]])
randn_tensor = torch.randn(shape)
randn_tensor
# tensor([[-0.1649, -0.7466, 0.9215],
# [-0.3781, 0.2917, 0.0943]])
ones_tensor = torch.ones(shape)
ones_tensor
# tensor([[1., 1., 1.],
# [1., 1., 1.]])
zeors_tensor = torch.zeros(shape)
zeors_tensor
# tensor([[0., 0., 0.],
# [0., 0., 0.]])
empty_tensor = torch.empty(shape)
empty_tensor
# tensor([[ 5.5610e-33, 0.0000e+00, -2.0965e-29],
# [ 4.3412e-41, 8.9683e-44, 0.0000e+00]])
Tensor 속성
tensor = torch.rand(3, 4)
tensor.shape
# torch.Size([3, 4])
tensor.dtype
# torch.float32
tensor.device
# device(type='cpu')# device
torch.cuda.is_available()
# True
tensor
# tensor([[0.9595, 0.9310, 0.6591, 0.9092],
# [0.1513, 0.5509, 0.0415, 0.2907],
# [0.9306, 0.5788, 0.7953, 0.1504]])
tensor.device
# device(type='cpu')
if torch.cuda.is_available():
tensor = tensor.to('cuda')
tensor
# tensor([[0.9595, 0.9310, 0.6591, 0.9092],
# [0.1513, 0.5509, 0.0415, 0.2907],
# [0.9306, 0.5788, 0.7953, 0.1504]], device='cuda:0')
tensor.device
# device(type='cuda', index=0)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
tensor = tensor.to(device)
tensor.device
# device(type='cuda', index=0)
Tensor 연산
# Indexing and Slicing
data = [
[1, 2, 3], [4, 5, 6], [7, 8, 9]
]
tensor = torch.tensor(data, dtype=torch.float)
tensor
# tensor([[1., 2., 3.],
# [4., 5., 6.],
# [7., 8., 9.]])
tensor[2] # tensor[2, :], tensor[-1], tensor[-1, :]
# tensor([7., 8., 9.])
tensor[:, 2] # tensor[..., 2], tensor[:, -1], tensor[..., -1]
# tensor([3., 6., 9.])
tensor[1:, [2, 0]] # tensor[1:, [-1, 0]]
# tensor([[6., 4.],
# [9., 7.]])
tensor[1, 1] = 0
tensor
# tensor([[1., 2., 3.],
# [4., 0., 6.],
# [7., 8., 9.]])
tensor[:, 1] = 0
# tensor([[1., 0., 3.],
# [4., 0., 6.],
# [7., 0., 9.]])
tensor[1, :] = 0
# tensor([[1., 0., 3.],
# [0., 0., 0.],
# [7., 0., 9.]])# Joining Tensors
t1 = torch.tensor([[1, 2], [3, 4]])
t2 = torch.tensor([[5, 6], [7, 8]])
t1.shape, t2.shape
# (torch.Size([2, 2]), torch.Size([2, 2]))
torch.cat((t1, t2), dim=0)
# tensor([[1, 2],
# [3, 4],
# [5, 6],
# [7, 8]])
torch.cat((t1, t2), dim=1)
# tensor([[1, 2, 5, 6],
# [3, 4, 7, 8]])
tmp = torch.stack((t1, t2), dim=0)
tmp.shape
# torch.Size([2, 2, 2])
tmp
# tensor([[[1, 2],
# [3, 4]],
#
# [[5, 6],
# [7, 8]]])
tmp = torch.stack((t1, t2), dim=1)
tmp.shape
# torch.Size([2, 2, 2])
tmp
# tensor([[[1, 2],
# [5, 6]],
#
# [[3, 4],
# [7, 8]]])# Arithmetic Operations
a = torch.randn(2, 3)
b = torch.randn(3, 3)
torch.mm(a, b).shape
# tensor([[ 0.8420, 0.8749, 0.3478],
# [-4.2446, -3.9200, 0.3403]])a = torch.randn(1, 4)
b = torch.randn(4, 1)
torch.mul(a, b)
# tensor([[-0.7112, 0.5616, -0.2559, -0.2134],
# [-3.5239, 2.7827, -1.2678, -1.0573],
# [-1.0239, 0.8086, -0.3684, -0.3072],
# [-2.6151, 2.0650, -0.9408, -0.7846]])a = torch.zeros(256, 5, 6)
b = torch.zeros(256, 6, 7)
torch.bmm(a, b).shape
# torch.Size([256, 5, 7])
c = a @ b
c.shape
# torch.Size([256, 5, 7])a = torch.zeros((256, 5, 6))
b = torch.zeros((6, 7))
torch.matmul(a, b).shape
# torch.Size([256, 5, 7])# Single Element Tensors
tensor = torch.randn(4)
agg = tensor.sum()
agg
# tensor(1.6689)
type(agg)
# torch.Tensor
agg_item = agg.item()
type(agg_item)
# float# Inplace Operations
tensor = torch.randn(4)
tensor
# tensor([0.4042, 0.6806, 2.1352, 0.5675])
tensor.add(5)
# tensor([5.4042, 5.6806, 7.1352, 5.5675])
tensor
# tensor([0.4042, 0.6806, 2.1352, 0.5675])
tensor.add_(5)
# tensor([5.4042, 5.6806, 7.1352, 5.5675])
tensor
# tensor([5.4042, 5.6806, 7.1352, 5.5675])
Dimension Change
tensor = torch.rand(2, 3, 4)
tensor.shape
# torch.Size([2, 3, 4])
tensor.reshape(2, 12).shape
# torch.Size([2, 12])
tensor.reshape(3, -1).shape
# torch.Size([3, 8])
tensor.reshape(3, -1, 2).shape
# torch.Size([3, 4, 2])tensor.shape
# torch.Size([2, 3, 4])
tensor.permute(2, 1, 0).shape
# torch.Size([4, 3, 2])tensor = torch.rand(1, 3, 1, 20, 1)
tensor.shape
# torch.Size([1, 3, 1, 20, 1])
tensor.squeeze().shape
# torch.Size([3, 20])
tensor.squeeze(dim=0).shape
# torch.Size([3, 1, 20, 1])
tensor.unsqueeze(dim=0).shape
# torch.Size([1, 1, 3, 1, 20, 1])
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 28일차. PyTorch - Model Layers & Regression (0) | 2025.02.19 |
|---|---|
| 27일차. PyTorch - Dataset (0) | 2025.02.18 |
| 25일차. AutoML & XAI & Pipeline (0) | 2025.02.14 |
| 24일차. Imbalanced Data & Cross Validation (0) | 2025.02.13 |
| 23일차. Unsupervised Learning (0) | 2025.02.12 |



