더보기
12일 차 회고.
단위 프로젝트를 본격적으로 시작해야 하는 날이었다. 팀원들에게 작업을 분배하고, 문제가 생기면 이를 해결해야 하는데 아는 것도 별로 없고 경험도 없어서 많이 힘들었다. 잘 따라와 주는 팀원들에게 고마웠다. 그리고 수업이 끝나고 6시 30분부터 PCCP 시험을 봤는데 불합격이 떴다. Python은 이번이 처음이라서 그럴 수도 있지만, 위험하다고 생각했다. 기업들에서는 필수로 코딩 테스트를 보는데 이대로면 바로 떨어질 것이 뻔하기 때문에 열심히 준비해야 할 것 같다.
1. Crawling
1-1. Comment Crawling
# crawling.py
import requests
from bs4 import BeautifulSoup as bs
def do_crawling_of_nate(comment_id: str):
# url = "https://pann.nate.com/talk/350939697"
url = f"https://pann.nate.com/talk/{comment_id}"
header = {
"Referer": "https://pann.nate.com/talk/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=header)
return response
def get_comments(comment_id:str) -> list:
response = do_crawling_of_nate(comment_id)
if response.status_code >= 400:
print("Error.")
return
beautiful_text = bs(response.text, "html.parser")
comments_list = beautiful_text.find_all("dd", class_="usertxt")
return [
comment.get_text().replace("\n", "").strip() for comment in comments_list
]
# main.py
import streamlit as st
from common.crawling import get_comments
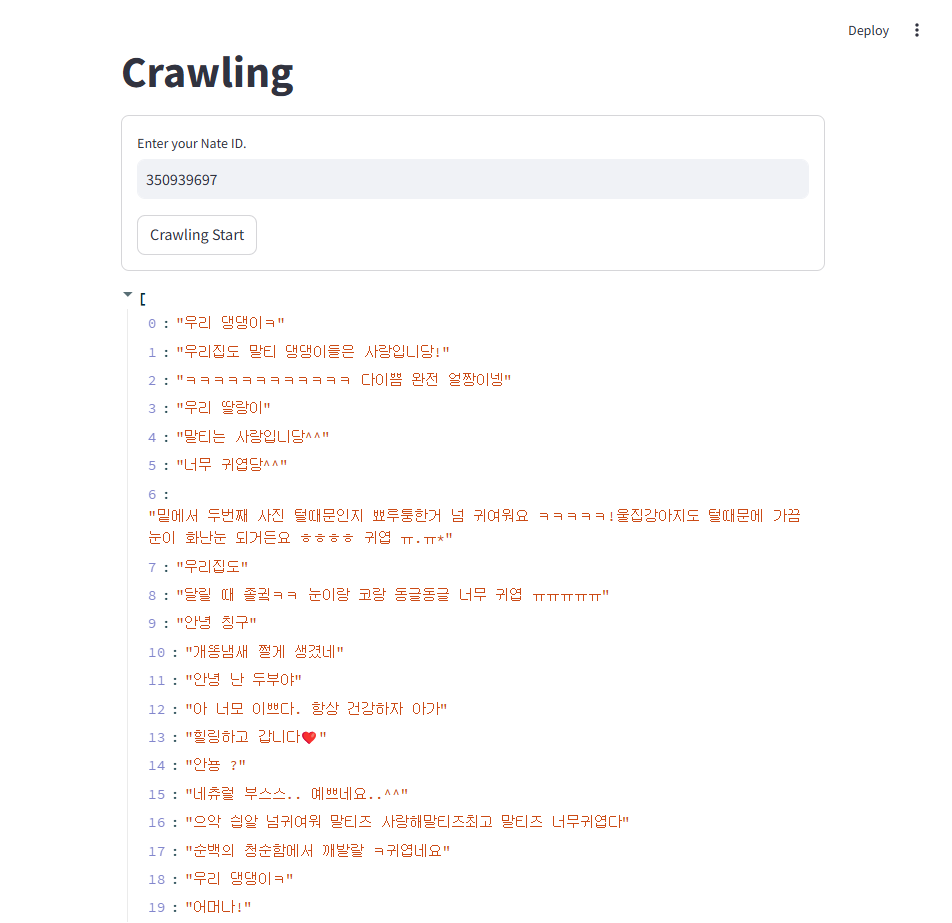
st.title("Crawling")
with st.form("my_form"):
nate_id = st.text_input(label="Enter your Nate ID.")
submit_button = st.form_submit_button(label="Crawling Start")
if submit_button and nate_id is not None:
msg = get_comments(nate_id)
st.write(msg)

1-2. 이름, 날짜, 내용
import requests
from bs4 import BeautifulSoup as bs
url = "https://pann.nate.com/talk/350939697"
header = {
"Referer": "https://pann.nate.com/talk/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=header)
if response.status_code >= 400:
print("Error.")
beautiful_text = bs(response.text, "html.parser")
dl_list = beautiful_text.find_all("dl", class_="cmt_item")
dl_list[0].find(class_="nameui").get_text().strip()
dl_list[0].find("i").get_text().strip()
dl_list[0].find("dd", class_="usertxt").get_text().replace("\n", "").strip()
1-2. MySQL
# 계정 생성
USE mysql;
CREATE USER 'nate_pan'@'%' IDENTIFIED BY 'n1234';
SELECT * FROM user;
# 데이터베이스 생성
CREATE DATABASE nate_db;
SHOW DATABASES;
USE nate_db;
# 계정 권한 부여
GRANT ALL PRIVILEGES ON nate_db.* TO 'nate_pan'@'%';

# 테이블 생성
CREATE TABLE IF NOT EXISTS nate_pann_comments (
comment_id int unsigned auto_increment comment '댓글 아이디',
pann_id varchar(20) not null comment '네이트 판 아이디',
title varchar(20) null comment '댓글 제목',
comment varchar(200) not null comment '댓글 내용',
create_dt timestamp not null comment '댓글 생성일자',
primary key(comment_id)
) engine=innodb default charset=utf8 comment='네이트 판 댓글';
SHOW TABLES;
# crawling.py
import requests
from datetime import datetime
from bs4 import BeautifulSoup as bs
def do_crawling_of_nate(comment_id: str):
url = f"https://pann.nate.com/talk/{comment_id}"
header = {
"Referer": "https://pann.nate.com/talk/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=header)
return response
def get_comments(comment_id:str) -> list:
response = do_crawling_of_nate(comment_id)
if response.status_code >= 400:
print("Error.")
return
beautiful_text = bs(response.text, "html.parser")
comment_list = beautiful_text.find_all("dl", class_="cmt_item")
return [
{
'pann_id': comment_id,
'create_dt': datetime.strptime(comment.find("i").get_text().strip(), '%Y.%m.%d %H:%M'),
'title': comment.find(class_="nameui").get_text().strip(),
'comment': comment.find("dd", class_="usertxt").get_text().replace("\n", "").strip()
} for comment in comment_list
]
# main.py
import streamlit as st
from common.crawling import get_comments
from common.database import insert_query
from common.sql_constant import INSERT_SQLs
st.title("Crawling")
with st.form("my_form"):
nate_id = st.text_input(label="Enter your Nate ID.")
submit_button = st.form_submit_button(label="Crawling Start")
if submit_button and nate_id is not None:
comments = get_comments(nate_id)
list_error = insert_query(INSERT_SQLs.NATE_PAN_COMMENTS, comments)
if not list_error:
st.write("Success.")
else:
st.write(list_error)
MySQL에 저장하기 위해 먼저 라이브러리를 설치한다.
pip install mysqlclient SQLAlchemy
# common\sql_constant.py
import enum
class INSERT_SQLs(enum.Enum):
NATE_PAN_COMMENTS = (enum.auto(), """
INSERT nate_pann_comments (pann_id, create_dt, title, comment)
VALUES('{pann_id}', '{create_dt}', '{title}', '{comment}');
""", "댓글 데이터 저장")
# common\database.py
import streamlit as st
from sqlalchemy import text
from .sql_constant import INSERT_SQLs
@st.cache_resource
def get_connector():
return st.connection("mydb", type="sql", autocommit=True)
def insert_query(sql_constant: INSERT_SQLs, datas: list) -> list:
conn = get_connector()
error_list = []
for data in datas:
try:
insert_sql = sql_constant.value[1].format(
pann_id=data['pann_id'], create_dt=data['create_dt'], title=data['title'], comment=data['comment']
)
conn.connect().execute(text(insert_sql))
except Exception as e:
data['error'] = str(e)
error_list.append(data)
return error_list
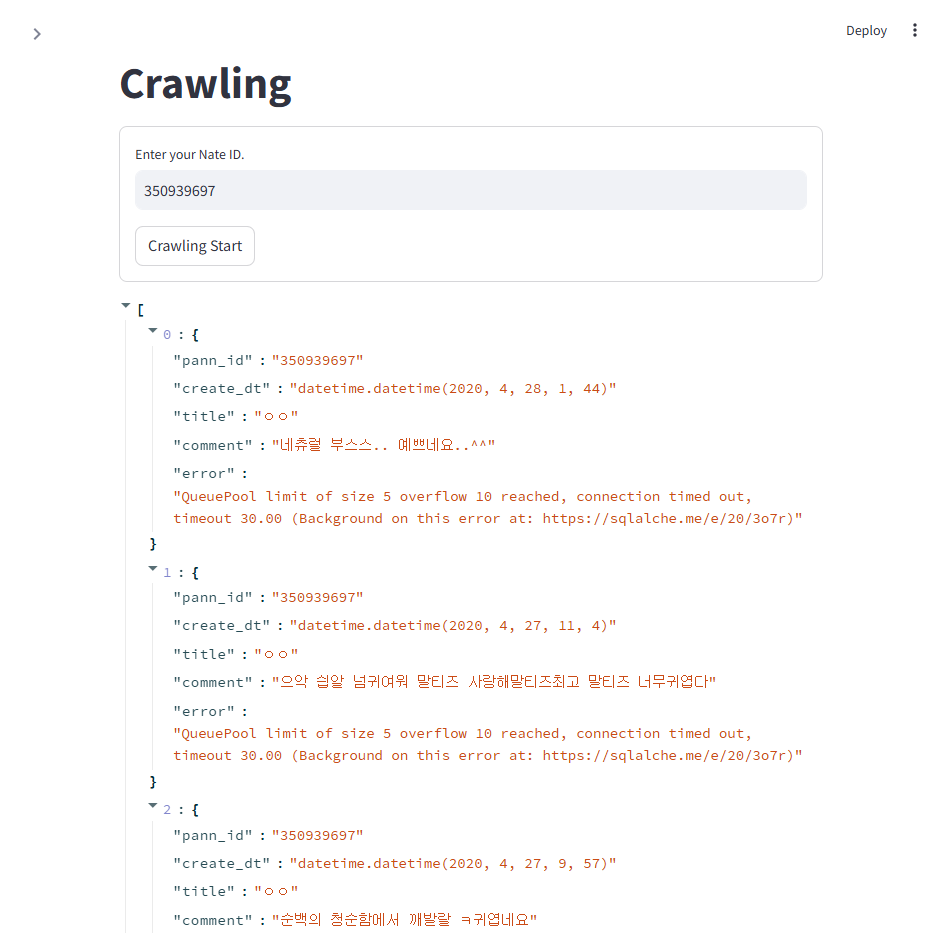
'nate_pann_comments' database에 저장된 것을 알 수 있다.

하지만 QueuePool Limit으로 인해서 에러가 발생한 것을 알 수 있다. 이는 추후 해결 방법을 알아볼 예정이다.
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 15일차. 데이터 분석 & Pandas (1) | 2025.01.31 |
|---|---|
| 13-14일차. 단위 프로젝트(프로그래밍과 데이터 기초) (0) | 2025.01.24 |
| 11일차. Git & Streamlit & Crawling (0) | 2025.01.21 |
| 10일차. DML & Streamlit (0) | 2025.01.20 |
| 9일차. DCL & DML (0) | 2025.01.17 |



