18일 차 회고.
ADsP 시험 날짜가 2월 22일인데, SQLD 시험 날짜가 3월 8일이라서 시간이 엄청 촉박할 것 같다. 그런데 여기에 이제 토이 프로젝트 개발이 본격적으로 시작되어서 시간을 잘 활용해야 할 것 같다.
1. Data Visualization - Seaborn
!pip install koreanize-matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import koreanize_matplotlib
import seaborn as sns
sns.set_theme(style="darkgrid")
1-1. Relational plots
두 변수의 관계를 볼 때 사용한다.
scatterplot
tips = sns.load_dataset("tips")
tips.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 244 entries, 0 to 243
# Data columns (total 7 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 total_bill 244 non-null float64
# 1 tip 244 non-null float64
# 2 sex 244 non-null category
# 3 smoker 244 non-null category
# 4 day 244 non-null category
# 5 time 244 non-null category
# 6 size 244 non-null int64
# dtypes: category(4), float64(2), int64(1)
# memory usage: 7.4 KB
tips.head()
sns.replot(data=tips, x="total_bill", y="tip", kind="scatter")
sns.replot(data=tips, x="total_bill", y="tip", hue="smoker", style="time")
sns.replot(data=tips, x="total_bill", y="tip", hue="size", size="size", sizes=(15, 200))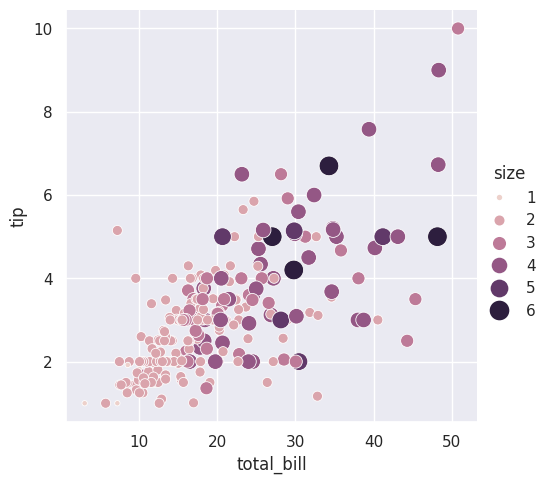
sns.relplot(data=tips, x="total_bill", y="tip", hue="smoker", col="time")
lineplot
fmri = sns.load_dataset("fmri")
fmri.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 1064 entries, 0 to 1063
# Data columns (total 5 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 subject 1064 non-null object
# 1 timepoint 1064 non-null int64
# 2 event 1064 non-null object
# 3 region 1064 non-null object
# 4 signal 1064 non-null float64
# dtypes: float64(1), int64(1), object(3)
# memory usage: 41.7+ KB
fmri.head()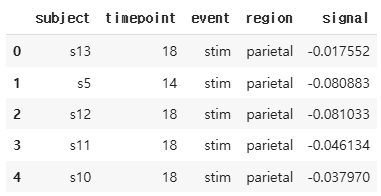
sns.relplot(data=fmri, x="timepoint", y="signal", kind="line")
sns.relplot(data=fmri, x="timepoint", y="signal", kind="line", estimator=None)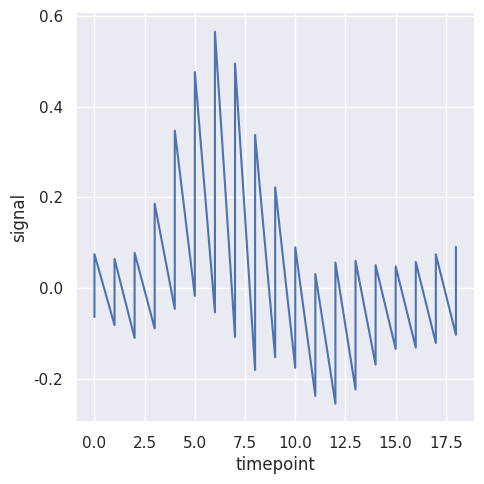
sns.relplot(data=fmri, x="timepoint", y="signal", kind="line",
hue="region", style="event", dashes=False, markers=True)
sns.relplot(data=fmri, x="timepoint", y="signal", kind="line",
hue="subject", col="region", row="event", height=3, estimator=None)
2. Data Preprocessing
2-1. Pandas EDA
데이터 종류
- 정형 데이터(Structured Data)
- 고정된 필드에 저장된 데이터
- ex. 관계형 데이터베이스, 스프레드시트(엑셀) 등
- 반정형 데이터(Semi-Structured Data)
- 고정된 필드에 저장되어 있지는 않지만, 메타데이터나 스키마 등을 포함하는 데이터
- ex. XML, HTML, JSON, 이메일 등
- 비정형 데이터(Unstructured Data)
- 고정된 필드에 저장되어 있지 않은 데이터
- ex. 텍스트, 이미지, 동영상, 음성 데이터 등
데이터 유형
- 수치형 데이터(Quantitative Data)
- 수치형 데이터는 수치를 값으로 가지기 때문에, 수학적인 활용이 가능하다.
- ex. 히스토그램
-
- 연속형 데이터(Continuous Data)
- 더 작은 단위로 나눌 수 있다.
- 이산형 데이터(Discrete Data)
- 더 작은 단위로 나눌 수 없다.
- 연속형 데이터(Continuous Data)
- 범주형 데이터(Categorical Data)
- 범주형 데이터는 범주 또는 그룹으로 나타나는 데이터로, 수치를 가지더라도 수학적인 활용이 불가능하다.
- ex. 막대 그래프
-
- 순서형 데이터(Ordinal Data)
- 순서 관계가 있다.
- 명목형 데이터(Nominal Data)
- 순서 관계가 없다.
- 순서형 데이터(Ordinal Data)
데이터 누수(Data Leakage)
데이터 누수는 미래에 대한 전혀 알 수 없는 정보가 모델학습에서 사용된 경우를 말한다.
즉, 평가 데이터가 모델의 학습에 이용된 경우로, 학습 데이터와 평가 데이터를 물리적으로 분리해야 한다.
탐색적 데이터 분석(EDA; Exploratory Data Analysis)
EDA는 데이터를 분석하고 결과를 도출하는 과정에 있어서 지속적으로 해당 데이터에 대한 탐색과 이해를 기본적으로 가져야 한다는 것을 말한다.
분석 방법
- 상관계수
- 두 변수 사이의 상관관계의 정도를 나타내는 수치
- 특징
- 상관계수는 항상 -1과 1 사이에 있다.
- 상관계수의 절댓값의 크기는 직선관계에 가까운 정도를 나타낸다.
- 상관계수의 부호는 관계의 방향을 나타낸다.
- 상관계수가 0에 가까울수록 상관관계가 없다.
- 상관계수는 단위가 없다.
- 인지하지 못한 여러 잠재변수가 있을 수 있기 때문에, 큰 상관계수 값이 항상 두 변수 사이의 인과관계를 의미하지는 않는다.

- 왜도
- 데이터 분포의 비대칭도를 나타내는 통계량
- 해석
- -0.5 ~ 0.5: 상당히 대칭적
- -1 ~ -0.5 또는 0.5 ~ 1: 적당히 치우침
- -1보다 작거나 1보다 큰 경우: 상당히 치우침
- 분포가 왼쪽으로 치우쳐져 있고, 오른쪽으로 긴 꼬리를 가진 경우, 왜도는 양수의 값을 가진다.
- 평균 > 중앙값 > 최빈값
- 정규분포와 같이 좌우 대칭인 경우, 왜도는 0에 가까워진다.
- 평균 = 중앙값 = 최빈값
- 분포가 오른쪽으로 치우쳐져 있고, 왼쪽으로 긴 꼬리를 가진 경우, 왜도는 음수의 값을 가진다.
- 평균 < 중앙값 < 최빈값
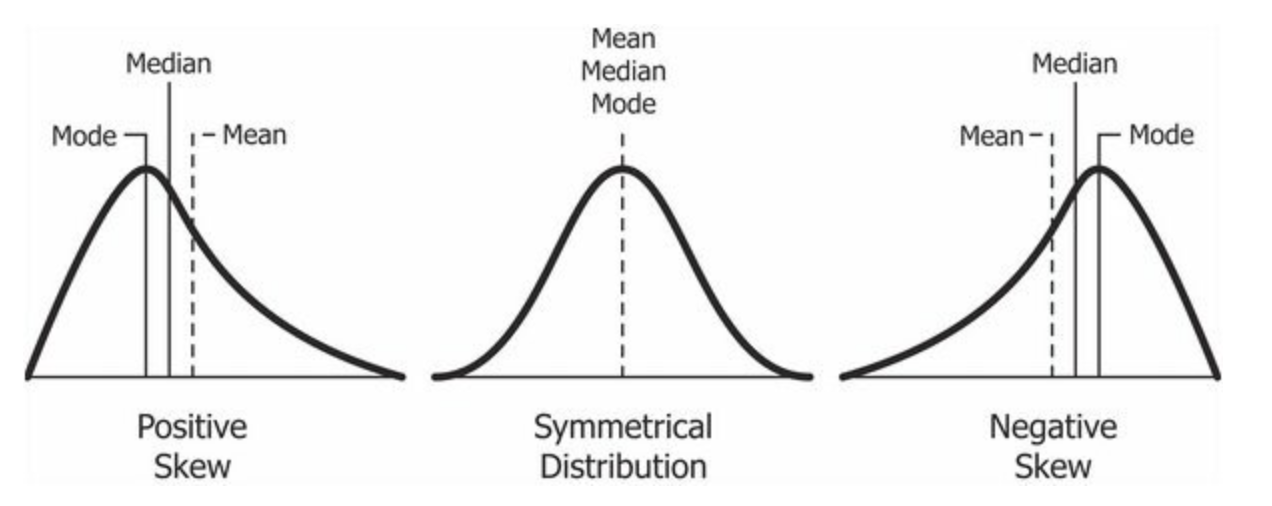
- 첨도
- 확률 분포의 뾰족한 정도를 나타내는 지표
- 해석
- Mesokurtic(첨도 = 3): 정규 분포와 유사한 첨도 통계량
- Leptokurtic(첨도 > 3): 피크가 Mesokurtic보다 높고 날카롭기 때문에 특이치가 많다는 것을 의미한다.
- Platykurtic(첨도 < 3): 피크가 Mesokurtic보다 낮고 넓기 때문에, 특이치가 부족하다는 것을 의미한다.
- 첨도값이 0보다 작을 경우, 정규분포보다 더 완만하고 납작한 분포를 가진다.
- 첨도값이 0보다 클 경우, 정규분포보다 더 뾰족한 분포를 가진다.
- 이상치
- 데이터에 이상치가 있으면 왜곡된 의미를 전달할 가능성이 높다.
- 박스플롯을 활용하면 이상치가 얼마나 포함되어 있는지를 쉽게 판단할 수 있다.
타이타닉 - Load Dataset
# 데이터 분석 라이브러리
import pandas as pd
import numpy as np
# 시각화 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('titanic')
df.shape # (891, 15)
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 891 entries, 0 to 890
# Data columns (total 15 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 survived 891 non-null int64
# 1 pclass 891 non-null int64
# 2 sex 891 non-null object
# 3 age 714 non-null float64
# 4 sibsp 891 non-null int64
# 5 parch 891 non-null int64
# 6 fare 891 non-null float64
# 7 embarked 889 non-null object
# 8 class 891 non-null category
# 9 who 891 non-null object
# 10 adult_male 891 non-null bool
# 11 deck 203 non-null category
# 12 embark_town 889 non-null object
# 13 alive 891 non-null object
# 14 alone 891 non-null bool
# dtypes: bool(2), category(2), float64(2), int64(4), object(5)
# memory usage: 80.7+ KB
df_head()
df_tail()
타이타닉 - 수치형 데이터
df_number = df.select_dtypes(include=np.number)
df_number.shape # (891, 6)
df_number.describe()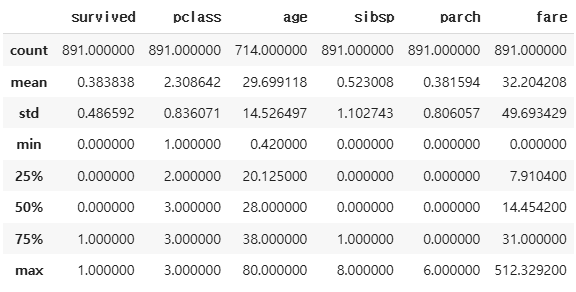
- 수치형 데이터 중 범주형 데이터: survived, pclass, sibsp, parch
- 수치형 데이터: age, fare
타이타닉 - 범주형 데이터
df_object = df_select_dtypes(exclude=np.number)
df_object.shape # (891, 9)
df_object.describe()
- 삭제할 데이터: embarked, class, alive
- 확인할 데이터: who, adult_male
- 결측치가 있는 데이터: deck, embark_town
타이타닉 - 데이터 수정
df['survived'] = df['survived'].astype(str)
df['pclass'] = df['pclass'].astype(str)
df['sibsp'] = df['sibsp'].astype(str)
df['parch'] = df['parch'].astype(str)
df.drop(['embarked', 'alive', 'class'], axis=1, inplace=True)
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 891 entries, 0 to 890
# Data columns (total 12 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 survived 891 non-null object
# 1 pclass 891 non-null object
# 2 sex 891 non-null object
# 3 age 714 non-null float64
# 4 sibsp 891 non-null object
# 5 parch 891 non-null object
# 6 fare 891 non-null float64
# 7 who 891 non-null object
# 8 adult_male 891 non-null bool
# 9 deck 203 non-null category
# 10 embark_town 889 non-null object
# 11 alone 891 non-null bool
# dtypes: bool(2), category(1), float64(2), object(7)
# memory usage: 65.7+ KB
타이타닉 - 수치형 데이터 분석 - 통계 분석
df_number.describe()
타이타닉 - 수치형 데이터 분석 - 왜도 분석
df_number['age'].skew() # 0.38910778230082704
df_number['age'].plot.hist(bins=50)
df_number['age_log'] = np.log(df_number['age'])
df_number['age'].skew(), df_number['age_log'].skew()
# (0.38910778230082704, -2.299848848658492)
sns.distplot(df_number['age_log'])
df_number['age_sqrt'] = np.sqrt(df_number['age'])
df_number['age'].skew(), df_number['age_sqrt'].skew()
# (0.38910778230082704, -0.6609802729981862)
sns.distplot(df_number['age_sqrt'])
타이타닉 - 수치형 데이터 분석 - 첨도 분석
df_number['fare'].kurt() # 33.39814088089868
df_number['fare'].plot.hist(bins=50)
df_number['fare_log'] = np.log1p(df_number['fare'])
df_number['fare'].kurt(), df_number['fare_log'].kurt()
# (33.39814088089868, 0.976142106683104)
sns.distplot(df_number['fare_log'])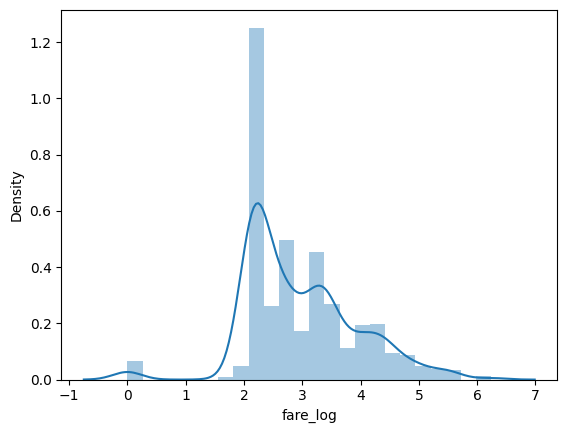
df_number['fare_sqrt'] = np.log1p(df_number['fare'])
df_number['fare'].kurt(), df_number['fare_sqrt'].kurt()
# (33.39814088089868, 6.282211915236795)
sns.distplot(df_number['fare_sqrt'])
타이타닉 - 수치형 데이터 분석 - 이상치 분석
sns.boxplot(data_df_number, y=df_number['age'])
sns.boxplot(data_df_number, y=df_number['age_log'])
sns.boxplot(data_df_number, y=df_number['age_sqrt'])


sns.boxplot(data_df_number, y=df_number['fare'])
sns.boxplot(data_df_number, y=df_number['fare_log'])
sns.boxplot(data_df_number, y=df_number['fare_sqrt'])


타이타닉 - 상관관계 분석
df_number.corr()
df_number.plot(kind='scatter', x='age_log', y='age_sqrt')
df_number.plot(kind='scatter', x='age_log', y='fare_log')
sns.heatmap(
df_number.corr(), vmin=-1, vmax=1, annot=True,
linewidths=0.2, cmap="coolwarm"
)
df['survived'] = df['survived'].astype(int)
df['pclass'] = df['pclass'].astype(int)
df_number = df.select_dtypes(include=np.number)
df_number.columns
# Index(['survived', 'pclass', 'age', 'fare'], dtype='object')
df_number.corr()
df_number.plot(kind='scatter', x='pclass', y='fare')
sns.heatmap(
df_number.corr(), vmin=-1, vmax=1, annot=True,
linewidths=0.2, cmap="coolwarm"
)
타이타닉 - 교차분석
pd.crosstab(index=df['sex'], columns=df['survived'], margins=True, normalize="all")
pd.crosstab(index=df['sex'], columns=df['survived'], margins=True, normalize="columns")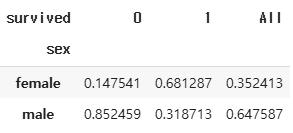
pd.crosstab(index=df['sex'], columns=df['survived'], margins=True, normalize="index")
df_pivot = pd.pivot_table(
df, index='pclass', columns='sex', values='survived',
aggfunc=['mean', 'sum']
)
df_pivot
2-2. Data Cleaning
Data Cleaning
- 완결성
- 가능하면 결측값을 제거한다.
- 유일성
- 중복 데이터가 있으면 안 된다.
- 통일성
- 동일한 데이터 형식 및 단위로 기록되어 있어야 한다.
- 가능하면 정규화를 한다.
- 가능하면 이상치를 제거한다.
결측치(Missing Value)
- 결측치 표현
- NaN(Not a Number): 숫자가 아님
- Null: 존재하지 않음
- undefined: 정의되어 있지 않음
- 결측치 유형
- 완전 무작위 결측(MCAR; Missing Completely At Random)
- 어떤 특성의 결측치가 다른 특성의 값들과 아무런 상관관계가 없는 경우
- 데이터를 입력한 이가 실수를 했거나, 전산상의 에러가 난 경우
- 무작위 결측(MAR; Missing At Random)
- 다른 특성의 값에 따라 결측치의 발생 확률이 계산되지만, 값 자체의 상관관계는 알 수 없는 경우
- 비무작위 결측(NMAR; Not Missing At Random)
- 결측치가 일어난 특성의 값이 다른 특성의 값과 상관관계가 있는 경우
- 완전 무작위 결측(MCAR; Missing Completely At Random)
결측치 처리
- 제거
- 결측치 비율: 10% 미만
- 결측치가 발생한 행 또는 열을 삭제한다.
- 치환
- 결측치 비율: 10% 미만
- 결측치를 적당한 방법(평균, 중앙값, 최빈값 등)으로 대체한다.
- 모델 기반 처리
- 결측치 비율: 10% 이상
- 결측치를 예측하는 새로운 모델을 구성하고, 이를 기반으로 결측치를 채운다.
타이타닉 - Load Dataset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('titanic')
df.shape # (891, 15)
타이타닉 - 유일성 처리
df.drop_duplicates(keep='first', inplace=True, ignore_index=True)
df.shape # (784, 15)
타이타닉 - 완결성 처리
(df.isnull().sum(axis=0) / df.shape[0]).round(4).sort_values(ascending=False)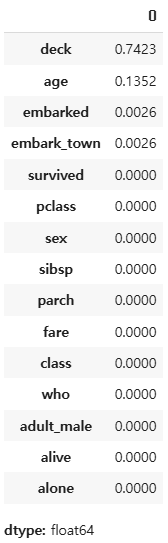
df.drop(['deck'], axis=1, inplace=True)
df.shape # (784, 14)
df.dropna(subset=['embarked', 'embark_town'], inplace=True)
df.shape # (782, 14)
(df.isnull().sum(axis=0) / df.shape[0]).round(4).sort_values(ascending=False)
df['age'].mean(), df['age'].median()
# (29.809792899408283, 28.0)
df['age_mean'] = df['age'].fillna(df['age'].mean())
df['age_median'] = df['age'].fillna(df['age'].median())
df['age'].mean(), df['age_mean'].mean(), df['age_median'].mean()
# (29.809792899408283, 29.809792899408286, 29.564475703324806)
df[['age', 'age_mean', 'age_median']].isnull().sum().sort_values(ascending=False)
from sklearn.impute import SimpleImputer
imputer = SimpleInputer(strategy="mean")
imputer.fit(df[["age"]])
df['age_simple_mean'] = imputer.transform(df[["age"]])
df[['age', 'age_simple_mean']].isnull().sum()
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
imputer.fit(df[["age"]])
df['age_knn'] = imputer.transform(df[["age"]])
df[['age', 'age_knn']].isnull().sum()
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
imputer = IterativeImputer(random_state=42)
imputer.fit(df[["age"]])
df['age_iter_none'] = imputer.transform(df[["age"]])
df[['age', 'age_iter_none']].isnull().sum()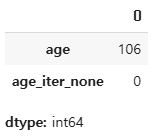
from sklearn.ensemble import RandomForestRegressor
imputer = IterativeImputer(
estimator=RandomForestRegressor(verbose=0, random_state=42),
max_iter=10, verbose=0,
imputation_order='ascending', random_state=42)
imputer.fit(df[["age"]])
df['age_random'] = imputer.transform(df[["age"]])
df[['age', 'age_randome']].isnull().sum()
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 20일차. Feature Extraction & Data Encoding (0) | 2025.02.07 |
|---|---|
| 19일차. Machine Learning & Data Preprocessing (0) | 2025.02.07 |
| 17일차. Data Visualization (1) | 2025.02.04 |
| 16일차. Pandas & Data Visualization (0) | 2025.02.03 |
| 15일차. 데이터 분석 & Pandas (1) | 2025.01.31 |



