더보기
20일 차 회고.
머신러닝 부분은 진도도 빠르고 봐야 할 코드가 늘어나서 따가라기 조금 힘든 것 같다. 주말 동안 토이 프로젝트를 진행하고 남는 시간 동안 이번 주에 배운 내용들을 쭉 복습해야겠다.
예제 One Hot Encoding부터 수정
1. Feature Extraction
1-1. 데이터타입
X_tr.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 712 entries, 0 to 711
# Data columns (total 10 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 survived 712 non-null int64
# 1 pclass 712 non-null int64
# 2 name 712 non-null object
# 3 sex 712 non-null object
# 4 age 712 non-null float64
# 5 sibsp 712 non-null int64
# 6 parch 712 non-null int64
# 7 ticket 712 non-null object
# 8 fare 712 non-null float64
# 9 embarked 712 non-null object
# dtypes: float64(2), int64(4), object(4)
# memory usage: 55.8+ KB
수치형 데이터 타입 변환
df_number = X_tr.select_dtypes(include=np.number)
df_number.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 712 entries, 0 to 711
# Data columns (total 6 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 survived 712 non-null int64
# 1 pclass 712 non-null int64
# 2 age 712 non-null float64
# 3 sibsp 712 non-null int64
# 4 parch 712 non-null int64
# 5 fare 712 non-null float64
# dtypes: float64(2), int64(4)
# memory usage: 33.5 KB
# survived
X_tr["survived"] = X_tr["survived"].astype("int32")
X_te["survived"] = X_te["survived"].astype("int32")
# pclass
X_tr['pclass'].unique() # array([1, 2, 3])
X_tr["pclass"] = X_tr["pclass"].astype("category")
X_te["pclass"] = X_te["pclass"].astype("category")
# age
X_tr["age"] = X_tr["age"].astype("int32")
X_te["age"] = X_te["age"].astype("int32")
# sibsp
X_tr['sibsp'].unique() # array([0, 1, 4, 3, 2, 8, 5])
X_tr["sibsp"] = X_tr["sibsp"].astype("category")
X_te["sibsp"] = X_te["sibsp"].astype("category")
# parch
X_tr['parch'].unique() # array([0, 2, 1, 6, 4, 3, 5])
X_tr["parch"] = X_tr["parch"].astype("category")
X_te["parch"] = X_te["parch"].astype("category")
X_tr.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 712 entries, 0 to 711
# Data columns (total 10 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 survived 712 non-null int32
# 1 pclass 712 non-null category
# 2 name 712 non-null object
# 3 sex 712 non-null object
# 4 age 712 non-null int32
# 5 sibsp 712 non-null category
# 6 parch 712 non-null category
# 7 ticket 712 non-null object
# 8 fare 712 non-null float32
# 9 embarked 712 non-null object
# dtypes: category(3), float32(1), int32(2), object(4)
# memory usage: 33.6+ KB
범주형 데이터 타입 변환
df_object = X_tr.select_dtypes(include='object')
df_object.head()
# sex
X_tr['sex'] = X_tr['sex'].astype('category')
X_te['sex'] = X_te['sex'].astype('category')
# embarked
X_tr['embarked'] = X_tr['embarked'].astype('category')
X_te['embarked'] = X_te['embarked'].astype('category')
X_tr.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 712 entries, 0 to 711
# Data columns (total 10 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 survived 712 non-null int32
# 1 pclass 712 non-null category
# 2 name 712 non-null object
# 3 sex 712 non-null category
# 4 age 712 non-null int32
# 5 sibsp 712 non-null category
# 6 parch 712 non-null category
# 7 ticket 712 non-null object
# 8 fare 712 non-null float32
# 9 embarked 712 non-null category
# dtypes: category(5), float32(1), int32(2), object(2)
# memory usage: 24.1+ KB
1-2. 문자열
공백제거
X_tr["name"] = X_tr["name"].map(lambda x: x.strip())
X_tr["ticket"] = X_tr["ticket"].map(lambda x: x.strip())
X_te["name"] = X_te["name"].map(lambda x: x.strip())
X_te["ticket"] = X_te["ticket"].map(lambda x: x.strip())
df_object.head()
문자열 포함 여부
dict_designation = {
'Mr.': '남성',
'Master.': '남성',
'Sir.': '남성',
'Miss.': '미혼 여성',
'Mrs.': '기혼 여성',
'Ms.': '미혼/기혼 여성',
'Lady.': '숙녀',
'Mlle.': '아가씨',
# 직업
'Dr.': '의사',
'Rev.': '목사',
'Major.': '계급',
'Don.': '교수',
'Col.': '군인',
'Capt.': '군인',
# 귀족
'Mme.': '영부인',
'Countess.': '백작부인',
'Jonkheer.': '귀족'
}
def add_designation(name):
designation = "unknown"
for key in dict_designation.keys():
if key in name:
designation = key
break
return designation
X_tr['designation'] = X_tr['name'].map(lambda x: add_designation(x))
X_te['designation'] = X_te['name'].map(lambda x: add_designation(x))
문자열 분리
def get_last_name(name):
last_name = None
try:
for key in dict_designation.keys():
if key in name:
name = name.replace(key,'')
last_name = name.split(',')[1].strip()
except:
pass
return last_name
X_tr['last_name'] = X_tr['name'].map(lambda x: get_last_name(x))
X_te['last_name'] = X_te['name'].map(lambda x: get_last_name(x))
X_tr['first_name'] = X_tr['name'].map(lambda x: x.split(',')[0].strip())
X_te['first_name'] = X_te['name'].map(lambda x: x.split(',')[0].strip())
def add_ticket_number(ticket):
try:
ticket_split = ticket.split(' ')
return int(ticket_split[-1])
except:
return 0
X_tr['ticket_number'] = X_tr['ticket'].map(lambda x: add_ticket_number(x)).astype("int32")
X_te['ticket_number'] = X_te['ticket'].map(lambda x: add_ticket_number(x)).astype("int32")
1-3. 집계
피봇 테이블
df_pivot = pd.pivot_table(X_tr, index='pclass', values='fare', aggfunc='mean').reset_index()
df_pivot.rename(columns = {'fare' : 'fare_mean_by_pclass'}, inplace = True)
df_pivot
print(f'before: {X_tr.shape}') # before: (712, 14)
X_tr = pd.merge(X_tr,df_pivot,how="left",on="pclass")
X_te = pd.merge(X_te,df_pivot,how="left",on="pclass")
print(f'after: {X_tr.shape}') # after: (712, 15)
X_tr[['pclass', 'fare', 'fare_mean_by_pclass']].head()
그룹
agg_dict = {
"survived" : "mean" ,
"sibsp" : "nunique",
"parch" : "nunique" }
df_groupby = X_tr.groupby("pclass").agg(agg_dict).reset_index()
df_groupby.rename(
columns = {
'survived' : 'survived_by_pclass',
'sibsp' : 'len_sibsp_by_pclass',
'parch' : 'len_parch_by_pclass'},
inplace = True)
df_groupby
print(f'before: {X_tr.shape}') # before: (712, 15)
X_tr = pd.merge(X_tr,df_groupby,how="left",on="pclass")
X_te = pd.merge(X_te,df_groupby,how="left",on="pclass")
print(f'after: {X_tr.shape}') # after: (712, 18)
1-4. 데이터 변환/조합
def sub_age(age):
return age // 10
X_tr['sub_age'] = X_tr['age'].map(lambda x: sub_age(x))
X_te['sub_age'] = X_te['age'].map(lambda x: sub_age(x))
def add_sub_embarked(row):
return str(row['embarked']) + str(row['pclass']) + str(row['sibsp']) + str(row['parch'])
X_tr['sub_embarked'] = X_tr.apply(lambda row: add_sub_embarked(row), axis=1)
X_te['sub_embarked'] = X_te.apply(lambda row: add_sub_embarked(row), axis=1)
1-5. 날짜
df_cinemaTicket.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 142524 entries, 0 to 142523
# Data columns (total 14 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 film_code 142524 non-null int64
# 1 cinema_code 142524 non-null int64
# 2 total_sales 142524 non-null int64
# 3 tickets_sold 142524 non-null int64
# 4 tickets_out 142524 non-null int64
# 5 show_time 142524 non-null int64
# 6 occu_perc 142399 non-null float64
# 7 ticket_price 142524 non-null float64
# 8 ticket_use 142524 non-null int64
# 9 capacity 142399 non-null float64
# 10 date 142524 non-null object
# 11 month 142524 non-null int64
# 12 quarter 142524 non-null int64
# 13 day 142524 non-null int64
# dtypes: float64(3), int64(10), object(1)
# memory usage: 15.2+ MB
datetime 적용
df_cinemaTicket['date'] = pd.to_datetime(df_cinemaTicket['date'])
df_cinemaTicket.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 142524 entries, 0 to 142523
# Data columns (total 14 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 film_code 142524 non-null int64
# 1 cinema_code 142524 non-null int64
# 2 total_sales 142524 non-null int64
# 3 tickets_sold 142524 non-null int64
# 4 tickets_out 142524 non-null int64
# 5 show_time 142524 non-null int64
# 6 occu_perc 142399 non-null float64
# 7 ticket_price 142524 non-null float64
# 8 ticket_use 142524 non-null int64
# 9 capacity 142399 non-null float64
# 10 date 142524 non-null datetime64[ns]
# 11 month 142524 non-null int64
# 12 quarter 142524 non-null int64
# 13 day 142524 non-null int64
# dtypes: datetime64[ns](1), float64(3), int64(10)
# memory usage: 15.2 MB
df_cinemaTicket # Date
df_cinemaTicket['date'].dt.year # Year
df_cinemaTicket['date'].dt.month # Month
df_cinemaTicket['date'].dt.day # Day
df_cinemaTicket['date'].dt.quarter # Quarter
df_cinemaTicket['date'].dt.weekday # Weekday
df_cinemaTicket['date'].dt.dayofyear # Day of year
1-6. 진행바(tqdm)
!pip install tqdm
from tqdm.auto import tqdm
2. Data Encoding
2-1. 라이브러리 임포트
!pip install category_encoders
import numpy as np
import pandas as pd
import category_encoders as ce
2-2. 변수 유형
수치형 데이터(Quantitative Data)
- 수치를 값으로 가지기 때문에, 수학적인 활용이 가능하다.
- 연속형 데이터(Continuous Data)
- 이산형 데이터(Discrete Data)
범주형 데이터
- 범주 또는 그룹으로 나타나는 데이터로, 수치를 가지더라도 수학적인 활용이 불가능하다.
- 순서형 데이터(Ordinal Data)
- 순서 관계가 있다.
- 명목형 데이터(Nominal Data)
- 순서 관계가 없다.
2-3. 데이터 인코딩
Normal Encoding
- One hot Encoding
- Feature가 늘어날수록 차원도 늘어난다.
data = {'color': ['Red', 'Blue', 'Green']}
df = pd.DataFrame(data)
df.head()
encoder = ce.OneHotEncoder(use_cat_names=True) # Encoding 객체 생성
df_encoded = encoder.fit_transform(df) # Encoding 객체 fit(학습), transform(변환)
df_encoded.head()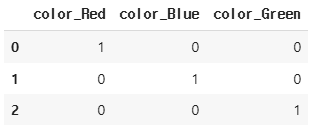
- Mean Encoding
data = {'Pincode': ['753001', '753002', '753003', '753001', '753004', '753002', '753002', '753001', '753003'],
'O/P': [1, 1, 0, 0, 1, 0, 1, 0, 1]} # O/P: 'Pincode'와 상관관계가 높은 수치형 데이터
df = pd.DataFrame(data)
df
group_mean = df.groupby('Pincode')['O/P'].mean()
df['Mean'] = df.['Pincode'].map(group_mean)
df.head()
Ordinal Encoding
- Label Encoding
data = {'column': ['Btech', 'Masters', 'High School', 'PHD']}
df = pd.DataFrame(data)
df.head()
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df['column_encoded'] = encoder.fit_transform(df['column'])
df.head()
- Target Encoding
data = {'Column': ['Btech', 'PHD', 'Masters', 'High School', 'PHD', 'Btech', 'Masters', 'High School', 'High School'],
'O/P': [1, 1, 0, 0, 1, 0, 0, 0, 1]} # O/P: 'Column'과 상관관계가 없는 데이터
df = pd.DataFrame(data)
df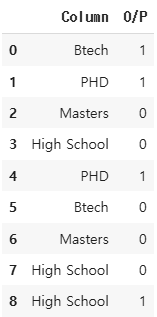
encoder = ce.TargetEncoder()
df_encoded = encoder.fit_transform(df['Column'], df['O/P'])
df['encoded'] = df_encoded['Column']
df['Rank'] = df['encoded'].rank(method='dense', ascending=False) # Label
df
- Ordinal Encoding
df = pd.DataFrame(
{'Fruit': ['시과', '딸기', '바나나', '수박', '포도',
'메론','자두','체리','화이트베리', '무화과'],
'color':['red1','red2','yellow','red','purple','green','light red','pink','white','brown'],
'price': [2000,300,400, 30000, 150, 8000,1000,100,300,800]})
df.head()
encoder = ce.OrdinalEncoder(cols = 'color')
df_encoded = encoder.fit_transform(df)
df_encoded.head()
2-4. 예제
결과 저장
results = []
모델 정의
from sklearn.tree import DecisionTreeClassifier
SEED = 42
데이터 로드
import seaborn as sns
df = sns.load_dataset('titanic')
cols = ['age','sibsp','parch','fare','pclass','sex','embarked', 'survived']
df = df[cols]
df.shape # (891, 8)
데이터 분리
from sklearn.model_selection import train_test_split
SEED=42
train, test = train_test_split(df, random_state=SEED, test_size=0.2)
train.shape, test.shape # ((712, 8), (179, 8))
결측치 제거
train.age = train.age.fillna(train.age.mean())
test.age = test.age.fillna(train.age.mean())
train['embarked'] = train.embarked.fillna(train.embarked.mode().values[0])
test.embarked = test.embarked.fillna(train.embarked.mode().values[0])
train.isnull().sum().sum(), test.isnull().sum().sum() # (0, 0)
cols = ['age','fare']
features_tr = train[cols]
target_tr = train['survived']
features_te = test[cols]
target_te = test['survived']
features_tr.shape, target_tr.shape # ((712, 2), (712,))
cols_encoding = ["pclass","sex","embarked","sibsp","parch"]
tmp_tr = train[cols_encoding]
tmp_te = test[cols_encoding]
tmp_tr.shape # (712, 5)
tmp_tr.head()
tmp_tr['sex'] = tmp_tr['sex'].map({'male':1, 'female':0})
tmp_tr['embarked'] = tmp_tr['embarked'].map({'S':2, 'C':1, 'Q':0})
tmp_te['sex'] = tmp_te['sex'].map({'male':1, 'female':0})
tmp_te['embarked'] = tmp_te['embarked'].map({'S':2, 'C':1, 'Q':0})
tmp_tr.head()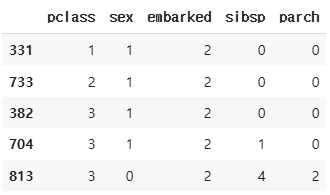
tmp_tr.isnull().sum().sum(), tmp_te.isnull().sum().sum() # (0, 0)
One hot Encoding
Mean Encoding
Target Encoding
결과 확인
results
# [{'encoding': 'one-hot',
# 'tr_score': 0.9803370786516854,
# 'te_score': 0.776536312849162}]
pd.DataFrame(results).sort_values(by=['te_score', 'tr_score'], ascending=[False, False])
3. Data Scaling and Transformer
3-1. 라이브러리 임포트
# 데이터 분석용
import pandas as pd
import numpy as np
# 데이터 시각화용
import matplotlib.pyplot as plt
import seaborn as sns
# 머신러닝 모듈
import sklearn
from sklearn.model_selection import train_test_split # Dataset 분리
from sklearn.tree import DecisionTreeClassifier # 지도학습 - 분류 모델
from sklearn.datasets import make_blobs # Dataset
3-2. 데이터 로드
# X: Feature _: Target
X, _ = make_blobs(n_samples= 200, centers= 5, random_state=4, cluster_std=1.5)
X_train, X_test = train_test_split(X, random_state=5, test_size=.1)
plt.scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
plt.scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
plt.legend()
plt.show()
Normalizer
왜곡된 데이터는 정확한 인사이트를 얻기 힘들기 때문에, 추천하지 않는다.
from sklearn.preprocessing import Normalizer
scaler = Normalizer()
X_scaled = scaler.fit_transform(X_train) # X_train: 수치형 데이터
X_test_scaled = scaler.transform(X_test) # X_test: 수치형 데이터
fig, ax = plt.subplots(1,2,figsize=[15,5])
ax[0].scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
ax[0].scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
ax[0].set_title('original')
ax[1].scatter(X_scaled[:,0],X_scaled[:,1], c='b', label="train data set")
ax[1].scatter(X_test_scaled[:,0],X_test_scaled[:,1], c='r', label="test data set")
ax[1].set_title('Scaled')
plt.legend()
plt.show()
3-3. Transformer
Power Transformer
- 데이터를 정규 분포로 매핑하여 분산을 안정화하고 비대칭성을 최소화한다.
from sklearn.preprocessing import PowerTransformer
scaler = PowerTransformer()
X_scaled = scaler.fit_transform(X_train) # X_train: 수치형 데이터
X_test_scaled = scaler.transform(X_test) # X_test: 수치형 데이터
fig, ax = plt.subplots(1,2,figsize=[15,5])
ax[0].scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
ax[0].scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
ax[0].set_title('original')
ax[1].scatter(X_scaled[:,0],X_scaled[:,1], c='b', label="train data set")
ax[1].scatter(X_test_scaled[:,0],X_test_scaled[:,1], c='r', label="test data set")
ax[1].set_title('Scaled')
plt.legend()
plt.show()
Quantile Transformer
- 주변 이상치와 일반 데이터 사이의 거리를 줄인다.
- 기본적으로 1000개 분위를 사용하여 데이터를 균등분포시킨다.
- 이상치에 민감하지 않으며, 데이터를 0과 1 사이로 압축한다.
from sklearn.preprocessing import QuantileTransformer
scaler = QuantileTransformer()
X_scaled = scaler.fit_transform(X_train) # X_train: 수치형 데이터
X_test_scaled = scaler.transform(X_test) # X_test: 수치형 데이터
fig, ax = plt.subplots(1,2,figsize=[15,5])
ax[0].scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
ax[0].scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
ax[0].set_title('original')
ax[1].scatter(X_scaled[:,0],X_scaled[:,1], c='b', label="train data set")
ax[1].scatter(X_test_scaled[:,0],X_test_scaled[:,1], c='r', label="test data set")
ax[1].set_title('Scaled')
plt.legend()
plt.show()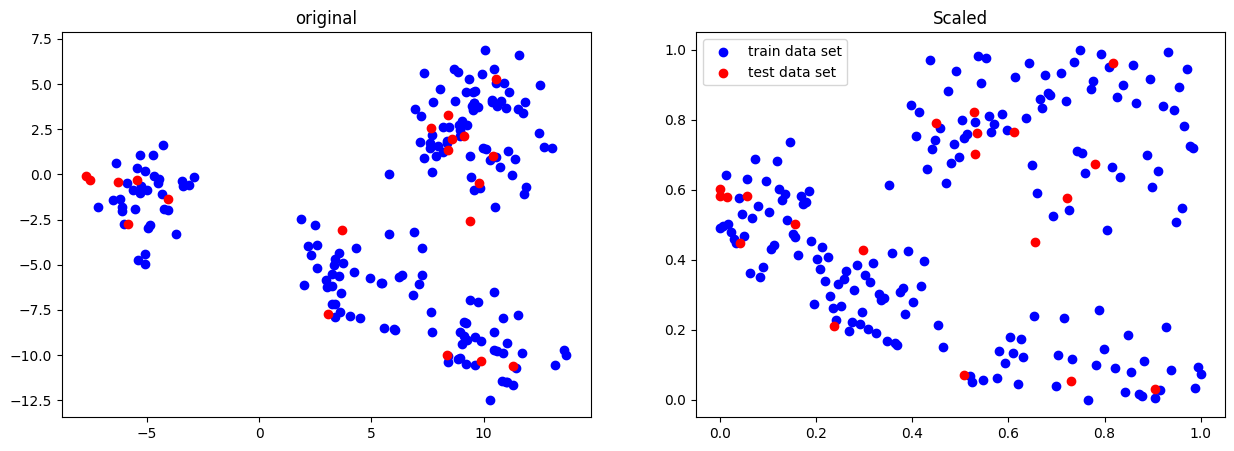
from sklearn.preprocessing import QuantileTransformer
# QuantileTransformer + 정규분포
scaler = QuantileTransformer(output_distribution = 'normal')
X_scaled = scaler.fit_transform(X_train) # X_train: 수치형 데이터
X_test_scaled = scaler.transform(X_test) # X_test: 수치형 데이터
fig, ax = plt.subplots(1,2,figsize=[15,5])
ax[0].scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
ax[0].scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
ax[0].set_title('original')
ax[1].scatter(X_scaled[:,0],X_scaled[:,1], c='b', label="train data set")
ax[1].scatter(X_test_scaled[:,0],X_test_scaled[:,1], c='r', label="test data set")
ax[1].set_title('Scaled')
plt.legend()
plt.show()
3-4. Scaler
Standard Scaler
- 평균을 0, 표준편차를 1로 변환한다.
- 주어진 데이터의 평균과 분산을 기준으로 표준화한다.
- 데이터가 정규분포를 따를 때 최적의 성능을 보인다.
- 이상치가 많을 때 적용하기 어렵다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_train) # X_train: 수치형 데이터
X_test_scaled = scaler.transform(X_test) # X_test: 수치형 데이터
fig, ax = plt.subplots(1,2,figsize=[15,5])
ax[0].scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
ax[0].scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
ax[0].set_title('original')
ax[1].scatter(X_scaled[:,0],X_scaled[:,1], c='b', label="train data set")
ax[1].scatter(X_test_scaled[:,0],X_test_scaled[:,1], c='r', label="test data set")
ax[1].set_title('Scaled')
plt.legend()
plt.show()
Min Max Scaler
- 최솟값과 최댓값 사이의 범위로 변환한다.
- 주어진 데이터의 최솟값과 최댓값을 기준으로 정규화한다.
- 모든 feature를 0과 1 사이의 데이터 값을 갖도록 만든다.
- 데이터의 상대적인 크기와 분포를 유지하여 정규화할 수 있다.
- 최솟값과 최댓값을 알고 있다면 원본 데이터로 변환하기 쉽다.
- 이상치에 영향을 가장 많이 받는다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X_train) # X_train: 수치형 데이터
X_test_scaled = scaler.transform(X_test) # X_test: 수치형 데이터
fig, ax = plt.subplots(1,2,figsize=[15,5])
ax[0].scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
ax[0].scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
ax[0].set_title('original')
ax[1].scatter(X_scaled[:,0],X_scaled[:,1], c='b', label="train data set")
ax[1].scatter(X_test_scaled[:,0],X_test_scaled[:,1], c='r', label="test data set")
ax[1].set_title('Scaled')
plt.legend()
plt.show()
Max Abs Scaler
- 모든 feature의 절댓값이 1 이하가 되도록 정규화한다.
- 0을 기준으로 절댓값이 가장 큰 수가 1 또는 -1의 값을 갖는다.
- 데이터가 양수일 때 효과적이다.
- 데이터의 분포가 0을 중심으로 대칭일 때 사용하기 적합하다.
- 이상치에 영향을 많이 받는다.
from sklearn.preprocessing import MaxAbsScaler
scaler = MaxAbsScaler()
X_scaled = scaler.fit_transform(X_train) # X_train: 수치형 데이터
X_test_scaled = scaler.transform(X_test) # X_test: 수치형 데이터
fig, ax = plt.subplots(1,2,figsize=[15,5])
ax[0].scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
ax[0].scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
ax[0].set_title('original')
ax[1].scatter(X_scaled[:,0],X_scaled[:,1], c='b', label="train data set")
ax[1].scatter(X_test_scaled[:,0],X_test_scaled[:,1], c='r', label="test data set")
ax[1].set_title('Scaled')
plt.legend()
plt.show()
Robust Scaler
- 중앙값과 IQR(Interquartile Range)을 기준으로 데이터를 변환한다.
- 이상치에 영향을 받지 않는다.
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
X_scaled = scaler.fit_transform(X_train) # X_train: 수치형 데이터
X_test_scaled = scaler.transform(X_test) # X_test: 수치형 데이터
fig, ax = plt.subplots(1,2,figsize=[15,5])
ax[0].scatter(X_train[:,0],X_train[:,1], c='b', label="train data set")
ax[0].scatter(X_test[:,0],X_test[:,1], c='r', label="test data set")
ax[0].set_title('original')
ax[1].scatter(X_scaled[:,0],X_scaled[:,1], c='b', label="train data set")
ax[1].scatter(X_test_scaled[:,0],X_test_scaled[:,1], c='r', label="test data set")
ax[1].set_title('Scaled')
plt.legend()
plt.show()
3-5. Transformer -> Scaler
- Scaler -> Transformer
- 두 그래프의 분포도가 달라질 수 있다.
- Transformer -> Scaler
- 두 그래프의 분포가 동일하다.
3-6. 예제
데이터 로드
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
cancer_df = pd.DataFrame(data=cancer.data, columns=cancer.feature_names)
cancer_df['target'] = cancer.target
cancer_df.shape # (569, 31)
모델 학습
- No Scaler
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=3)
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
no_scaler_score = round(dtc.score(X_test, y_test), 4)
print('모델의 정확도 :', no_scaler_score)
# 모델의 정확도 : 0.9035
X_train_data = X_train.reshape(13650,1)
plt.hist(X_train_data, bins=50, color= 'red', alpha = 0.7, density = True)
plt.title('before data scaling')
plt.show()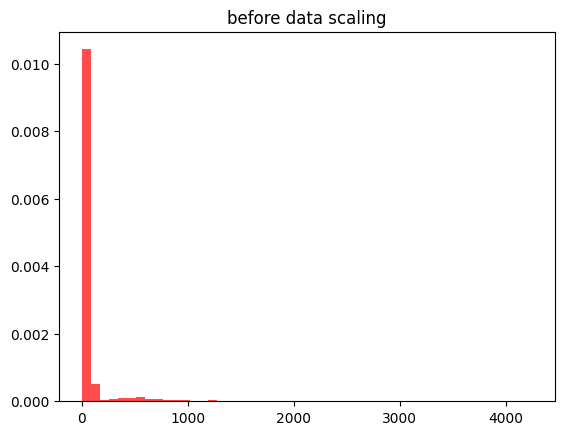
- Normalizer
- Power Transformer
- Quantile Transformer
- Standard Scaler
- MinMax Scaler
- Max Abs Scaler
- Robust Scaler
4. Supervised Learning - Classification - Model
4-1. 필수 라이브러리 임포트
!pip install --upgrade joblib==1.1.0
!pip install --upgrade scikit-learn==1.1.3
!pip install mglearn
import logging
logging.getLogger('matplotlib.font_manager').setLevel(logging.ERROR)
import mglearn
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
# import matplotlib.font_manager as fm
import seaborn as sns
%matplotlib inline
4-2. Classification Model
Linear Classification Model
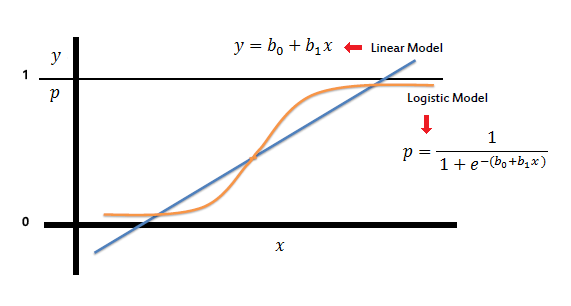
- Logsitic Regression
- 예측 결정으로 Sigmoid Function을 사용한다.
- Sigmoid Function
- 이진 분류 시 사용한다.
- Sigmoid Function
- 하이퍼파라미터(C)가 낮을수록 정규화가 강화된다.
- 예측 결정으로 Sigmoid Function을 사용한다.
ㅁ
- Linear SVM
- SVM: 클래스를 구분하는 분류 문제에서 각 클래스를 구분하는 선을 그어주는 방식
- 두 클래스의 가운데 선을 그을 때, 가장 가까이 있는 점들을 Support Vector라고 하며, 직선과 Support Vector 사이의 거리를 최대 margin이라고 한다.
- 하이퍼파라미터(C)가 낮을수록 정규화가 강화된다.
Decision Tree
- 여러 가지 규칙을 순차적으로 적용하며 트리기반의 규칙을 만들어 예측하는 알고리즘
- 데이터를 분할하는 데 순수도가 높은 방향으로 규칙을 정한다.
KNN
- 최근접 이웃 알고리즘
- 새로운 샘플이 K개의 가까운 이웃을 이용해서 예측한다.
'SK네트웍스 Family AI캠프 10기 > Daily 회고' 카테고리의 다른 글
| 22일차. Supervised Learning - Classification & Ensemble & HPO (0) | 2025.02.11 |
|---|---|
| 21일차. Supervised Learning - Regression & Classification (0) | 2025.02.10 |
| 19일차. Machine Learning & Data Preprocessing (0) | 2025.02.07 |
| 18일차. Data Visualization(Seaborn) & Data Cleaning (0) | 2025.02.05 |
| 17일차. Data Visualization (1) | 2025.02.04 |



